Info
home server 구축 과정을 정리한 페이지 입니다.
계획
미니pc 를 통해서 ProxmoxVE 를 OS 로 설치한 뒤 Opnsense kubernetes 등 여러가지 도구들을 사용하여 실제 여러 홈페이지 및 application 을 운영해 볼 생각입니다.
미니pc 스펙
모델명 : FIREBAT T8 플러스 N100 CPU : N100 (4core) Memory : 16GB storage : 512GB local : 100GB local-lvm : 375GB
사용할 기술 스택
코드 관리 & 배포
- Repository: GitHub (Private Repository)
- Registry: Docker Hub (Private Repository)
- CI/CD: Jenkins, ArgoCD
인프라 & 가상화
- HypervisorOS: Proxmox VE
- Container Orchestration: K3s (Kubernetes)
- Firewall/Load Balancer: OpnSense / HAProxy
- VPN: WireGuard
- Infrastructure as Code: Ansible
애플리케이션 스택
- Backend: Django (Python)
- Frontend Web: Flutter Web
- Mobile: Flutter
- Web Server: Nginx Ingress Controller
- API: Django REST Framework
- Async Tasks: Celery
데이터베이스
- Main Database: PostgreSQL
- Cache/Session: Redis
Analytics/Logs: MongoDB
모니터링 & 로깅
- Metrics: Prometheus
- Visualization: Grafana
- Log Storage: Elasticsearch
- Log Analysis: Kibana
- Log Collection: Fluentd
DevOps 도구
Code Quality: SonarQubeSecret Management: HashiCorp VaultData Pipeline: Apache AirflowAnalysis Environment: Jupyter Notebook
클라우드 & 외부 서비스
- Cloud Platform: AWS (연동)
- App Store: Google Play Store, Apple App Store
- SSL Certificate: Let’s Encrypt (자동 갱신)
- DNS: Cloudflare (도메인 관리)
개발 환경
- OS: Ubuntu 24.04(VM)
- Container Runtime: Docker
- Package Manager: Helm
- Development: Cursor / PyCharm
주의사항(보안사항)
GitHub에 올리면 안 되는 것 ❌ 데이터베이스 비밀번호 ❌ API 키, 토큰 ❌ 개인 정보 ❌ 내부 IP, 설정 정보
대안 ✅ Environment Variables ✅ Kubernetes Secrets ✅ HashiCorp Vault ✅ .env 파일 (gitignore 처리)
Docker Hub에 포함하지 않는 것 ❌ 데이터베이스 패스워드 ❌ API 키/시크릿 ❌ 개인정보 ❌ 인증서/키 파일
대신 사용 ✅ Environment Variables ✅ Kubernetes Secrets ✅ Docker Secrets ✅ 외부 설정 파일
균형잡힌 K8s 리소스 계획
물리 vs 할당 리소스
현재 미니 pc 의 spec 이 작아서, 오버커밋으로 구성하였습니다. (균형잡힌 오버커밋)
⚖️ BALANCED OVERCOMMIT 현황
| 구분 | 물리 | 할당 | 배수 | 안전성 |
|---|---|---|---|---|
| CPU | 4 Core | 20 vCPU | 5배 | ✅ 안전 |
| Memory | 15.41GB | 24GB | 1.56배 | ✅ 균형 |
| Disk | 512GB | 250GB | 0.49배 | ✅ 넉넉 |
주요사항:
- 메모리 오버커밋: 1.56배 (안전성 보장)
- 디스크 할당: 250GB (실용성 보장 및 추가 확장 가능)
VM 리소스 할당 (수정됨)
| VM | vCPU | Memory | Disk | 역할 | |
|---|---|---|---|---|---|
| OpnSense | 2 | 2GB | 20GB | 방화벽/라우터 | |
| K3s Master | 6 | 4GB | 30GB | 클러스터 컨트롤 플레인 | |
| K3s Worker-1 | 6 | 9GB | 100GB | 워커 노드 | |
| K3s Worker-2 | 6 | 9GB | 100GB | 워커 노드 |
오버커밋이 안전한 이유 (간단 정리)
1. 📊 실제 사용률 차이
예시 - PostgreSQL:
- 할당: 2GB
- 평상시: 800MB (40% 사용)
- 피크시: 1.5GB (75% 사용)
예시 - Jenkins:
- 할당: 2.5GB
- 대기중: 300MB (12% 사용)
- 빌드중: 2.2GB (88% 사용)2. ⏰ 시간대별 분산
실제 사용 패턴 예시:
- 09:00-12:00: Jenkins 빌드 (높은 사용률)
- 14:00-17:00: 개발/테스트 (중간 사용률)
- 02:00-04:00: Elasticsearch 인덱싱 (높은 사용률)
- 23:00-07:00: 대부분 서비스 대기 (낮은 사용률)
→ 전체 서비스가 동시 피크 사용할 확률 매우 낮음3. 🔄 메모리 공유 기술
KSM (Kernel Same-page Merging):
- Ubuntu 베이스 이미지: 4개 VM 공유
- Docker 베이스 레이어: 자동 중복 제거
- 시스템 라이브러리: 공통 부분 공유
→ 실제 메모리 사용량 30-40% 절약서비스별 메모리 사용 패턴 (현실적)
🔴 무거운 서비스들 (2GB 이상)
| 서비스 | 할당 | 평상시 | 피크시 | 사용 시간대 |
|---|---|---|---|---|
| Jenkins | 2.5GB | 0.3GB | 2.2GB | 업무시간 빌드 |
| Elasticsearch | 2.5GB | 1.2GB | 2.3GB | 새벽 인덱싱 |
| Django API (2개) | 4GB | 2.5GB | 3.5GB | 사용자 트래픽 |
| Harbor | 2GB | 0.8GB | 1.8GB | 이미지 푸시시 |
| Prometheus | 2GB | 1.3GB | 1.8GB | 지속적 수집 |
🟡 중간 서비스들 (1-2GB)
| 서비스 | 할당 | 평상시 | 피크시 | 특징 |
|---|---|---|---|---|
| PostgreSQL | 2GB | 0.8GB | 1.5GB | 연결수에 따라 변동 |
| ArgoCD | 1.5GB | 0.9GB | 1.3GB | 배포시에만 증가 |
| MongoDB | 1.5GB | 0.7GB | 1.2GB | 로그 수집량에 따라 |
| Airflow | 1.5GB | 0.5GB | 1.3GB | 워크플로우 실행시 |
| Flutter Web (2개) | 3GB | 1.8GB | 2.5GB | 사용자 접속에 따라 |
🟢 가벼운 서비스들 (1GB 이하)
| 서비스 | 할당 | 평상시 | 피크시 | 특징 |
|---|---|---|---|---|
| Grafana | 1GB | 0.5GB | 0.8GB | 대시보드 조회시 증가 |
| Kibana | 1GB | 0.4GB | 0.7GB | 로그 검색시 증가 |
| Redis | 1GB | 0.3GB | 0.6GB | 캐시 데이터량에 따라 |
| Nginx | 0.5GB | 0.2GB | 0.4GB | 트래픽에 따라 선형 증가 |
워커 노드 장애 시나리오
시나리오 : 노드 장애 (중요)
Worker-1 다운 시:
→ 모든 Pod가 Worker-2로 이동
→ Worker-2 필요 메모리: 약 15GB
→ 할당 메모리: 9GB
Priority Class 적용:
1. PostgreSQL, Redis (시스템 중요): 유지
2. Django API (비즈니스): 유지
3. Prometheus, Grafana (모니터링): 유지
4. Jenkins, Harbor (개발): Pending 상태
5. Jupyter, 기타 (옵션): Pending 상태
결과: 핵심 서비스는 유지, 개발 도구는 일시 중단Important
Priority Class 를 활용해서 pod 우선순위를 정해두자.
- Priority Class 생성
- 각 Deployment에 priorityClassName 추가
- 테스트: 노드 drain 시뮬레이션
- 모니터링: 파드 스케줄링 확인
모니터링 방법은 다음과 같습니다.
# 모든 파드의 우선순위 확인
kubectl get pods -o custom-columns=\
NAME:.metadata.name,\
PRIORITY:.spec.priorityClassName,\
NODE:.spec.nodeName
# Pending 상태 파드 확인
kubectl get pods --field-selector=status.phase=Pending
# 파드 스케줄링 이벤트 확인
kubectl get events --sort-by=.metadata.creationTimestamp안전 운영 가이드 (추후 고민해볼 것)
1. 🎯 리소스 모니터링 임계값
메모리 사용률 알림:
- 75% 이상: 주의 (6.7GB)
- 85% 이상: 경고 (7.6GB)
- 95% 이상: 긴급 (8.5GB)
디스크 사용률 알림:
- 80% 이상: 주의 (80GB)
- 90% 이상: 경고 (90GB)
- 95% 이상: 긴급 (95GB)2. 🔄 자동 대응 전략
HPA (Horizontal Pod Autoscaler):
- Django API: CPU 70% → replica 증가
- Flutter Web: 메모리 80% → replica 증가
Priority Classes:
- system-critical: DB, Redis
- business-critical: Django, Nginx
- development: Jenkins, Harbor
- monitoring: Prometheus, Grafana
- optional: Jupyter, 기타3. 📊 성능 최적화
Resource Limits 설정:
- requests: 최소 보장 리소스
- limits: 최대 사용 제한
- 메모리 leak 방지
- OOM 위험 최소화
Node Affinity:
- DB 서비스: SSD 우선 배치
- 계산 집약적: CPU 성능 우선
- I/O 집약적: 네트워크 성능 우선다이어그램
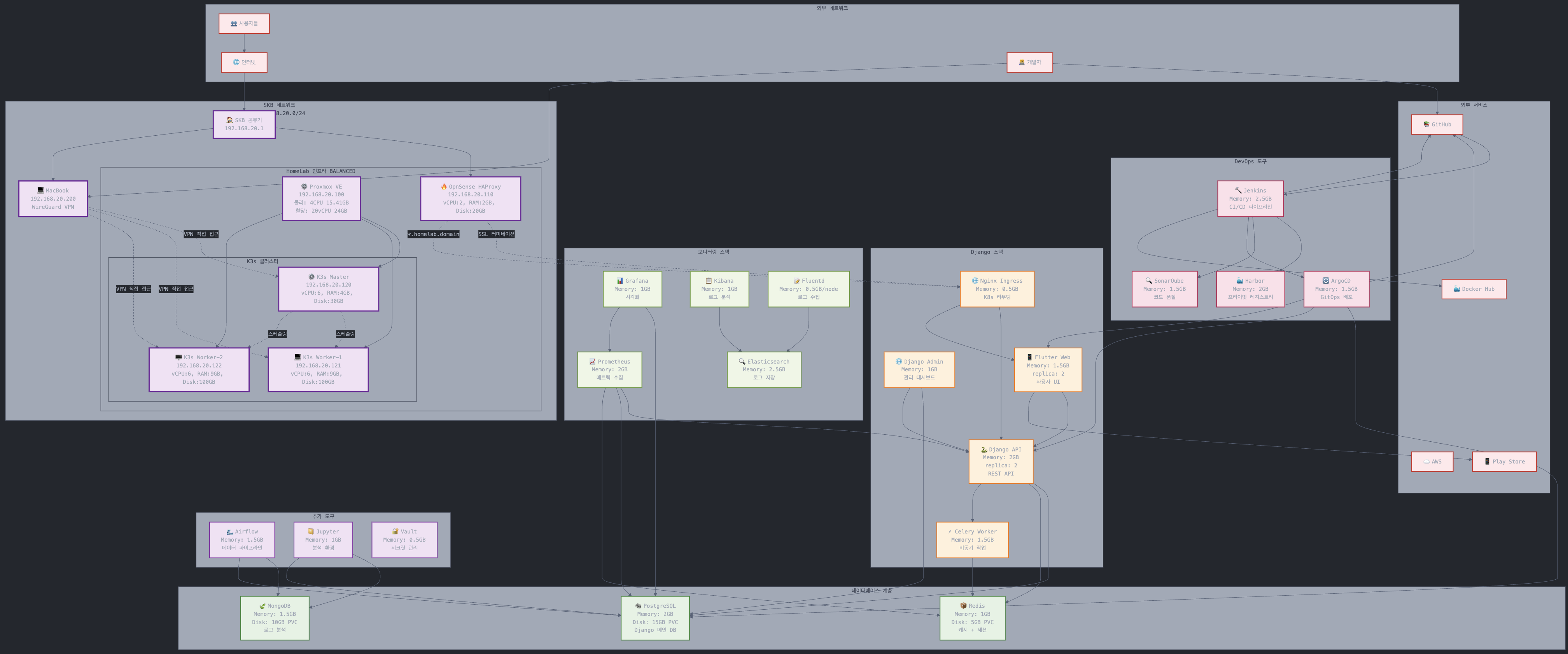
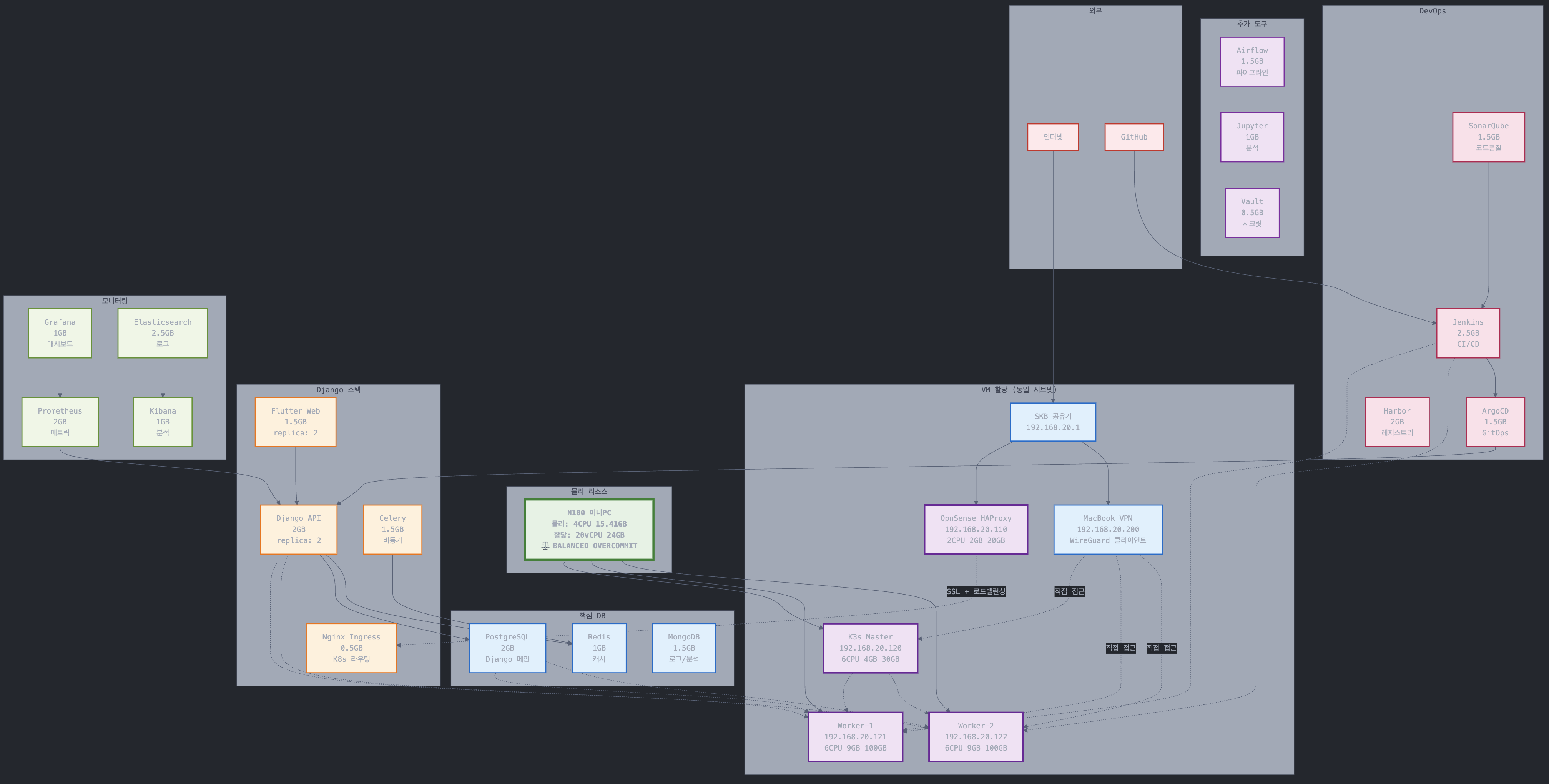
Info
K8s 클러스터에서는 실제로 서비스들이 특정 노드에 고정되지 않고, 클러스터 전체에 분산 배치 됩니다. 아래 다이어 그램은 “예상 배치 및 리소스 계획” 입니다.
더 간단하게 표현한 다이어그램.
외부 네트워크 통신
공유기 → opnsense (haproxy) →