1. Manual Scheduling
노드 위의 Pod를 수동으로 스케쥴링 하는 방법에 대해 알아보자.
스케쥴링 없이 Pod를 위치시키기 위해서는 직접 pod의 yaml 파일에 nodeName을 입력해주는 방법이 있다.
(pod 생성 시에만 가능하다)
만약 Pod 가 이미 생성되었는데 노드에 할당하고 싶다면?
바인딩 개체를 생성하고 Pod의 바인딩 API에 게시요청을 보내는 것이다. (실제 스케쥴러가 하는 일을 모방)
아래 예시처럼 nodeName을 입력하면 된다.
---apiVersion: v1kind: Podmetadata: name: nginxspec: nodeName: node01 containers: - image: nginx name: nginx2. Labels and Selectors
분류하기 위한 제일 좋은 방법은 Label을 활용하는 것이다.
쿠버네티스에서는 metadata 아래에 label을 만들어서 사용한다.
그리고 selectors를 활용해서 필요한 pod, service 등등을 label을 활용해서 찾아낸다.
예) Identify the POD which is part of the prod environment, the finance BU and of frontend tier?
controlplane ~ ➜ kubectl get pod --selector env=prod,bu=finance,tier=frontendNAME READY STATUS RESTARTS AGEapp-1-zzxdf 1/1 Running 0 5m18s3. Taints and Tolerations(허용)
Pod 와 Node 의 관계를 udemy에선 벌레(Pod)가 사람(Node)에게 접근하는 것과 유사한 비유로 설명했다.
Taint는 ‘방충 스프레이’와 같다. 일부 벌레들은 이 스프레이가 뿌려져 있는 곳에 접근을 못할 것이다.
그러나 일부 벌레들은 이런 스프레이에 면역이 있을 수 있다.
우리가 모기퇴치제를 뿌려도 모기에 물리는 것처럼 말이다.
Tolerations은 이런 벌레들이 가지고 있는 ‘면역력’ 같은 것이다.
pod가 생성되면 쿠버네티스 스케쥴러는 이 pod를 가능한 워커노드에 두려고 한다.
최초에 아무 설정이 없으면 균일하게 pod를 배포한다.
Taints는 특정 node에 모든 pod들이 접근하지 못하도록 한다.
일부 pod만 해당 node에 두고 싶다면 Tolerations을 Pod에 적용시켜 그 node에 두도록 한다.
여기서 가장 이해하기 쉬우려면 왜 Taints 라는걸 사용하는지 알면된다.
💡 노드에 테인트(taint)를 설정하면 해당 노드에 파드가 스케줄링되는 것(배치 되는것)을 제한할 수 있다.
이것은 파드가 특정 노드에 배치되는 것을 제어하는 데 사용된다.
이렇게 하면 특정 노드에만 특정 유형의 워크로드를 실행하거나, 노드에 특정 제약 사항을 적용할 수 있다.
이제 taint를 노드에 적용하는 방법에 대해 알아보자.
# 양식kubectl taint nodes node-name key=value:taint-effect # 예시kubectl taint nodes node1 app=blue:NoSchedule여기서 taint-effect는 총 3가지가 있다.
NoSchedule(taint가 있는 경우 pod는 해당 노드에 스케줄링 되지 않음)
PreferNoSchedule(해당 노드에 설치를 웬만하면 안한다)
NoExcute(새로운 pod 뿐 아니라 기존에 pod가 있다면 사용자가 거부하면 삭제되어야 됌)
예를 들어 NoSchedule 이라는 taint 효과를 사용하면 해당 노드에 “key=value” taint가 있는 경우 해당 노드에 스케줄링 되지 않는다.
이번에 pod 설정을 보자.
apiVersion:kind: Podmetadata: name: myapp-podspec: containers: - name: nginx-container image: nginx tolerations: - key: app operator: "Equal" value: "blue" effect: "NoSchedule"위와같이 pod를 실행하면 NoSchedule 테인트가 적용된 node에서 pod가 동작할 수 있다.
4. Node Selectors
여러개의 노드가 있을 때 리소스의 크기에 맞는 노드를 선택하게끔 도와준다.
우선 node에 Label을 달아줘야 한다.
kubectl label nodes <node-name <label-key>=<label-value> kubectl label nodes node-1 size=Large이후 pod의 yaml 파일에 nodeSelector 를 사용해서 원하는 node의 Label을 작성해주면 된다.
apiVersion:kind: Podmetadata: nameL: myapp-podspec: containers: - name: data-processor image: data-processor nodeSelector: size: Large하지만 만약 매우 많은 노드와 리소스들을 관리하게 된다면 Node Selectors 만으로는 힘들다.
5. Node Affinity
node affinity 의 기능은 특정 노드에 포드 배치를 제한하는 고급 기능을 제공한다.
예시)
apiVersion:kind: Podmetadata: nameL: myapp-podspec: containers: - name: data-processor image: data-processor affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: size operator: In values: - Large노드 어피니티에는 두 가지 필드가 있습니다.
- requiredDuringSchedulingIgnoredDuringExecution : ‘스케쥴링하는 동안 꼭 필요한’ 조건
- preferredDuringSchedulingIgnoredDuringExecution : ‘스케쥴링하는 동안 만족하면 좋은’ 조건입니다. 꼭 이 조건을 만족해야하는 것은 아니라는 의미입니다.
두 필드는 ‘실행 중에 조건이 바뀌어도 무시’합니다. 파드가 이미 스케줄링되어 특정 노드에서 실행 중이라면 중간에 해당 노드의 조건이 변경되더라도 이미 실행 중인 파드는 그대로 실행된다는 뜻입니다.
6. Taints and Tolerations vs Node Affinity
두가지 방식은 차이가 있다. 일단 공통적으로 둘다 들어올 수 있는 pod를 선택할 수 있지만
taints and tolerations 는 taints가 없는 node에 들어갈 수 도 있고,
node affinity 는 node에 원치 않는 pod가 들어올 수가 있다.
따라서 두가지를 함께 사용되어 원하는 node 와 pod 를 고정시킬 수 있다.
7. Daemon Sets
데몬셋(DaemonSet)은 여러 노드에 걸쳐 특정한 작업을 실행하기 위해 사용되는 리소스 타입이다.
데몬셋에 의해 관리되는 특정 포드는 각각의 노드 위에 하나씩, 총 5개의 포드 인스턴스가 실행된다.
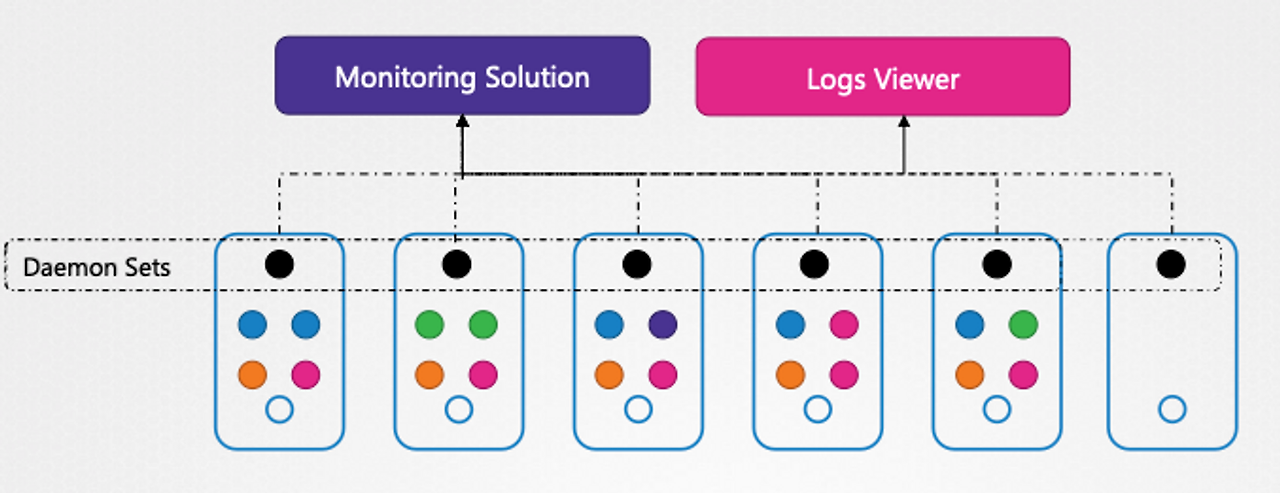
데몬셋의 주요 사용 사례는 다음과 같다.
-
모니터링 에이전트: 클러스터의 모든 노드에서 실행되어야 하는 모니터링 도구나 에이전트를 배포할 때 사용한다. 이를 통해 각 노드의 리소스 사용량, 성능 지표 등을 수집할 수 있다.
-
로그 컬렉터: 클러스터 내의 모든 노드에서 발생하는 로그를 수집하고 중앙 집중식 로그 저장소로 전송하는 로그 수집 에이전트를 데몬셋으로 배포할 수 있다. 이 방식으로 각 노드에서 생성되는 로그를 효율적으로 관리할 수 있다.
8. Static PODs
쿠버네티스에서, 대부분의 팟들은 API 서버를 통해 생성되고 관리된다.
/etc/kubernetes/mainfests 디렉터리 내의 파일이 조금이라도 바뀌면 kubelet이 pods 를 다시 만들게 된다.
kubelet이 스스로 만든 pod는 api 서버의 간섭이나 나머지 쿠버네티스 클러스터 구성요소들의 간섭을 받지 않는다.
스태틱 파드는 kubelet이 다이랙트로 controlplane 노드에서 관리되어지는 pod로써
kubelet은 /etc/kubernetes/manifests에 해당 pod의 구성파일(definition files )을 관리하며 kubelet 이 각각의 스태틱 파드를 감시한다. (만약 실패할 경우 다시 구동한다.)
etcd,
kube-apiserver,
kube-controller-manager,
kube-scheduler
4개의 pods를 말합니다.
/var/lib/kubelet/config.yaml 파일의 위치는 Linux 파일 시스템 내에서 Kubernetes 클러스터를 구성하는 노드의 kubelet 설정 파일
정적 팟(Static Pods)의 특징 정리
-
직접 관리: 정적 팟은 kubelet에 의해 직접 관리된다. kubelet은 주어진 디렉터리(/etc/kubernetes/manifests가 기본적인 경로)를 주시하며, 이 디렉터리 내에 있는 매니페스트 파일들로부터 팟을 생성한다.
-
API 서버 비존재: 이 팟들은 API 서버를 통해 생성되지 않는다. 따라서, API 서버의 간섭이나 나머지 쿠버네티스 클러스터 구성요소들의 간섭을 받지 않는다.
-
자동 재생성: /etc/kubernetes/manifests 디렉터리 내의 매니페스트 파일이 변경되면, kubelet은 해당 변경사항을 감지하고 팟을 다시 생성한다. 이는 정적 팟의 업데이트 또는 수정이 필요할 때 유용하다.
-
클러스터 구성요소 용도: 정적 팟은 주로 쿠버네티스 클러스터의 핵심 구성요소(예: kube-apiserver, kube-scheduler 등)를 실행하는 데 사용된다. 클러스터가 정상적으로 작동하기 위해 필요한 이러한 구성요소들은 kubelet에 의해 직접 관리될 수 있다.
use case
클러스터 부트스트랩: 쿠버네티스 클러스터 초기 설정 시, API 서버와 같은 핵심 구성요소를 실행하기 위해 정적 팟이 사용될 수 있다.
단일 노드 쿠버네티스 클러스터: 개발이나 테스트 목적으로 단일 노드 클러스터를 구성할 때, 정적 팟을 사용하여 간단하게 클러스터 구성요소를 배치할 수 있다.
9. Multiple Schedulers
스케쥴러는 여러개가 존재할 수 있다.
여러개를 사용 할 경우 반드시 이름이 달라야 한다.
보통 스케쥴러를 배포할 땐 pod로 배포한다.
그리고 스케쥴러를 새로 생성할 때 기존의 kube-system 네임스페이스에서 동작중이 scheduler 와 동일한 이미지를 사용해야 한다!!!
그리고 생성한 스케쥴러를 사용하여 pod 를 생성할 땐 아래 예시처럼 사용하면 된다.
apiVersion: v1kind: Podmetadata: name: annotation-default-scheduler labels: name: multischeduler-examplespec: schedulerName: "my-scheduler" containers: - name: pod-with-default-annotation-container image: registry.k8s.io/pause:2.010. Scheduler Profile
pods 를 생성할 때 scheduling Queue을 따라 생성되게 된다.
우선순위가 높은 순서대로 pods는 node에 배치된다.
이때 node의 리소스에 맞게 순서대로 배치된다.
이런것들을 조정해 주는 규칙?을 plug in 이라 한다.
그리고 KubeSchedulerConfiguration 파일 내에 여러개의 scheduler를 둘 수도 있다.
아래의 페이지들을 참고하면 scheduler에 대해 더 자세히 알 수 있다.
https://kubernetes.io/blog/2017/03/advanced-scheduling-in-kubernetes/