# 자동차 클래스를 정의
class Car:
def __init__(self, color, model):
self.color = color # 자동차의 색상
self.model = model # 자동차의 모델
self.speed = 0 # 초기 속도는 0
def accelerate(self, amount):
"""속도를 증가시키는 메서드"""
self.speed += amount
print(f"{self.model}의 속도가 {self.speed} km/h로 증가했습니다.")
def brake(self, amount):
"""속도를 감소시키는 메서드"""
self.speed -= amount
if self.speed < 0:
self.speed = 0 # 속도가 음수가 되지 않도록
print(f"{self.model}의 속도가 {self.speed} km/h로 감소했습니다.")
# 객체 생성
my_car = Car(color="Red", model="Ferrari")
# 메서드 호출
my_car.accelerate(50) # Ferrari의 속도가 50 km/h로 증가했습니다.
my_car.brake(20) # Ferrari의 속도가 30 km/h로 감소했습니다.
my_car.brake(40) # Ferrari의 속도가 0 km/h로 감소했습니다.코드 설명:
- 클래스 정의:
Car라는 클래스를 정의하고, 속성으로 색상(color), 모델(model), 속도(speed)를 설정합니다. 기능 + 속성 - 메서드 (기능):
accelerate: 주어진 양만큼 속도를 증가시킵니다.brake: 주어진 양만큼 속도를 감소시키고, 속도가 0보다 작아지지 않도록 합니다.
- 객체 생성:
my_car라는 이름의Car객체를 생성합니다. - 메서드 호출: 객체의 메서드를 호출하여 속도를 변경합니다.
객체지향
객체를 중심으로 데이터와 기능을 묶어 관리하며, 현실 세계를 모델링하는 데 강점
절차지향
함수와 절차를 중심으로 프로그램을 구성하며, 데이터와 기능이 분리되어 있어 비교적 단순한 구조로 작동
절차지향 프로그래밍의 특징
- 하나의 큰 기능을 처리하기 위해 작은 단위의 기능들로 나누어 처리하는 Top-Down 접근 방식으로 설계된다.
- 데이터와 함수를 별개로 취급한다.
- 모든 함수는 데이터 공유가 가능하다.
객체지향 프로그래밍 특징
프로그래밍에서 필요한 데이터를 추상화 시켜 상태와 행위를 가진 객체로 만들고 객체들간의 상호작용을 통해 로직을 구성하는 프로그래밍 방법이다.
장점
- 상속 캡슐화 다형성의 특징으로 코드를 재사용하거나 확장하기 좋아서 유지보수가 쉽다.
- 관련이 많은 객체의 상호작용을 생각해 실세계에 대한 모델링을 조금 더 쉽게 해준다.
- 캡슐화 특징으로 실제로 구현되는 부분을 외부에 드러나지 않도록 은닉하여 보안성이 높다.
단점
- 캡슐화와 격리구조 때문에 절차지향 프로그래밍보다 실행 속도가 느리다.
- 객체 단위의 구성으로 필요한 절차지향 프로그래밍보다 메모리 비용이 크다.
객체지향 프로그래밍 4가지 특징
추상화(abstraction)
구체적으로 정의하는 것이 아니라 필요한 정보만을 중심으로 간소화 하는 것을 말한다.
캡슐화(Encapsulation)
객체가 독립적인 역할을 할 수 있도록 데이터와 기능을 하나로 묶어서 관리하는 것을 말한다.
실제로 구현되는 부분을 외부에 드러나지 않도록 하여 정보를 은닉할 수 있다.
상속성(Inheritance)
하나의 클래스가 가진 데이터나 기능을 다른 클래스가 그대로 물려받는 것을 말한다. 기존 코드를 재사용하여 확장시킬 수 있다.
다형성(Polymorphism)
하나의 클래스나 메서드가 다양한 방식으로 동작이 가능한 것을 말한다.
오버라이딩(Overriding): 상속받은 자식 클래스에서 부모 클래스의 메서드와 같은 이름을 사용하고 매개변수와 리턴 타입도 같은 상태에서 기능을 재정의하는 것을 말한다.
오버로딩(Overloading): 같은 이름의 함수를 매개변수를 다르게 하여 기능을 재정의하는 것을 말한다.
객체지향 설계 원칙 5가지(SOLID)
단일 책임 원칙(Single responsibility principle)
한 클래스는 하나의 책임만 가지며 클래스는 그 책임을 완전히 캡슐화해야 함을 말한다.
개방-폐쇄 원칙(Open/closed principle)
소프트웨어 개체(클래스, 모듈, 함수 등)는 확장에 대해 열려 있어야 하고, 변경에 대해서는 닫혀 있어야 한다.
리스코프 치환 원칙(Liskov substitution principle)
프로그램의 객체는 프로그램의 정확성을 깨뜨리지 않으면서 하위 타입의 인스턴스로 바꿀 수 있어야 한다.
인터페이스 분리 원칙 (Interface segregation principle)
클라이언트가 자신이 이용하지 않는 메서드에 의존하지 않아야 한다. 큰 덩어리의 인터페이스를 구체적이고 작은 단위로 분리함으로써 클라이언트들이 꼭 필요한 메서드만 이용할 수 있게 한다.
의존관계 역전 원칙(Dependency inversion principle)
첫째, 상위 모듈은 하위 모듈에 의존해서는 안 된다. 상위 모듈과 하위 모듈 모두 추상화에 의존해야 한다.
둘째, 추상화는 세부 사항에 의존해서는 안 된다. 세부 사항이 추상화에 의존해야 한다.
추상 클래스와 인터페이스의 차이
-
추상클래스는 일반 메소드와 변수를 가질 수 있지만 인터페이스는 추상메소드와 상수변수만 가질 수 있다.
-
추상클래스는 단일상속만 가능하지만 인터페이스는 다중상속 가능하다.
-
추상클래스는 기능의 일부를 미리 구현해놓을 수 있지만 인터페이스는 기능을 정의만 한다.
-
하위클래스는 추상클래스를 확장하는데 사용되지만 인터페이스는 클래스에 기능을 제공하는 역할을 한다.
객체지향, 함수형의 차이
객체 중심의 설계, 함수 중심의 설계
클래스 디자인과 객체들의 관계 중심 코드, 값의 연산 및 결과 도출 중심 코드
클래스가 일급 객체, 함수 자체가 일급 객체
같은 인자값에 대해 다른 결과값이 반환될 수 있다. 항상 같은 결과값 반환된다.
자바 애플리케이션 JVM 실행 과정
JVM (Java Virtual Machine)은,
스택 기반의 가상 머신으로, Java가 OS에 구애받지 않고 재사용 가능하게 해주고 자바 바이트 코드를 실행할 수 있는 주체이다.
자바 프로그램 실행 과정이다.
- 프로그램이 실행되면 JVM은 OS로부터 프로그램이 필요로하는 메모리를 할당받는다. JVM은 이 메모리를 용도에 따라 여러 영역으로 나누어 관리한다.
- 자바 컴파일러 javac가 자바 소스 코드를 읽어들여 자바 바이트 코드 .class로 변환시킨다.
- Class Loader를 통해 class 파일들을 JVM으로 로딩한다.
- 로딩된 class 파일들은 Execution Engine을 통해 해석된다.
- 해석된 바이트코드는 Runtime Data Area에 배치되어 실질적인 수행이 이루어지게 된다. 이 실행과정 속에서 JVM은 필요에 따라 스레드 동기화와 GC같은 관리 작업을 수행한다.
자바 메모리 구조
Method Area
JVM이 실행되면서 생기는 공간이다.
Class 정보, 전역변수 정보, Static 변수 정보가 저장되는 공간이다.
Runtime Constant Pool 에는 말 그대로 ‘상수’ 정보가 저장되는 공간이다.
모든 스레드에서 정보가 공유된다.
Heap
new 연산자로 생성된 객체, Array와 같은 동적으로 생성된 데이터가 저장되는 공간
Heap에 저장된 데이터는 Garbage Collector 가 처리하지 않는한 소멸되지 않는다.
Reference Type 의 데이터가 저장되는 공간
모든 스레드에서 정보가 공유된다.
Stack
지역변수, 메소드의 매개변수와 같이 잠시 사용되고 필요가 없어지는 데이터가 저장되는 공간
Last In First Out, 나중에 들어온 데이터가 먼저 나간다
만약, 지역변수 이지만 Reference Type일 경우에는 Heap 에 저장된 데이터의 주소값을 Stack 에 저장해서 사용하게 된다.
스레드마다 하나씩 존재한다.
PC Register
스레드가 생성되면서 생기는 공간
스레드가 어느 명령어를 처리하고 있는지 그 주소를 등록한다.
JVM이 실행하고 있는 현재 위치를 저장하는 역할
Native Method Stack
Java 가 아닌 다른 언어 (C, C++) 로 구성된 메소드를 실행이 필요할 때 사용되는 공간
가비지 컬렉션이란?
자바나 코틀린 프로그램을 개발 하다 보면 유효하지 않은 메모리인 가비지(Garbage)가 발생하는데 이를 알아서 정리해주는 것이 가비지 콜렉터이다.
컬렉션 프레임워크
배열을 사용하다 보면 여러가지 비효율적인 문제가 생긴다. 가장 큰 문제점은 크기가 고정적이라는 것이다. 배열의 크기는 생성할 때 결정되며 그 크기를 넘어가게 되면 더이상 데이터를 저장할 수 없다. 또 데이터를 삭제하면 해당 인덱스의 데이터는 비어있어 메모리가 낭비되는 등 여러 문제점들이 발생한다. 그렇기에 자바는 배열의 이러한 문제점을 해결하기 위해, 널리 알려져 있는 자료구조를 바탕으로 객체나 데이터들을 효율적으로 관리(추가, 삭제, 검색, 저장)할 수 있는 자료구조들을 만들어 놓았다. 이러한 자료구조들이 있는 라이브러리를 컬렉션 프레임워크라고 한다. 대표적으로는 List, Set, Map, Stack, Queue 등이 있다.
Vector와 ArrayList의 차이
Vector는 한 번에 하나씩 쓰레드에서만 접근 가능
ArrayList는 동시에 여러 쓰레드에서 접근 가능
HashSet, TreeSet, LinkedHashSet 차이
HashSet 세트의 반복 순서를 보장하지 않거나 시간이 지나도 순서가 일정하게 유지된다.
→ 성능이 중요하고 요소의 순서가 중요하지 않은 경우 사용
TreeSet, 사용된 생성자에 따라 요소의 자연스러운 순서에 따라 또는 지정된 Comparator에 따라 반복된다.
→ 요소가 자연적인 순서를 사용하거나 Comparator에 의해 순서화되어야 할 때.
LinkedHashSet 요소가 집합에 삽입된 순서와 동일한 예측 가능한 반복 순서를 정의하는 모든 요소를 통해 이중 연결된 목록을 실행한다.
→ 요소의 삽입 순서를 유지해야 하는지 여부.
HashMap, LinkedHashMap, HashTable, TreeMap 차이
HashMap, LinkedHashMap, TreeMap, Hashtable 네 가지 모두 키(key)에서 값(value)으로의 대응 관계 가 있고 키를 기준으로 순회할 수 있다. 이 클래스들의 가장 큰 차이점은 시간 복잡도와 키가 놓이는 순서에 있다.
HashMap
검색과 삽입에 O(1) 시간이 소요된다.
키의 순서는 무작위로 섞여 있다.
구현은 연결리스트로 이루어진 배열로 되어 있다.
null key와 null value를 모두 허용 한다.
LinkedHashMap
검색과 삽입에 O(1) 시간이 소요된다.
키의 순서는 삽입한 순서대로 정렬되어 있다.
구현은 양방향 연결 버킷으로 구현되어 있다.
TreeMap
검색과 삽입에 O(log N) 시간이 소요된다.
키의 순서는 정렬되어 있다.
즉, 키는 반드시 Comparable 인터페이스를 구현하고 있어야 한다.
구현은 레드-블랙 트리로 구현되어 있다.
Hashtable
검색과 삽입에 O(1) 시간이 소요된다.
키의 순서는 무작위로 섞여 있다.
구현은 연결리스트로 이루어진 배열로 되어 있다.
null key와 null value를 모두 불허 한다.
동기화를 지원한다 (thread safe)
⇒ 따라서 Hashtable은 멀티스레드 환경에서 동작가능하며, 동기화를 지원하기 때문에 HashMap보다는 느리다.
일반적으로 별다른 이유가 없으면 HashMap 을 사용하는 것이 좋다. 일반적으로 빠르고 오버헤드가 적기 때문이다.
삽입한 순서대로 키 정보를 얻고 싶다면 LinkedHashMap
정렬된 순서대로 키 정보를 얻고 싶다면 TreeMap
병렬 처리를 하면서 자원의 동기화를 고려해야 하는 상황이라면 Hashtable
Servlet 개념, 생명주기
Servlet은,
자바 플랫폼에서 웹 앱을 개발할 때 사용하는 핵심기술로, 서버에서 웹페이지 등을 동적으로 생성하거나 데이터 처리를 수행하기 위해 자바로 작성된 프로그램이다. Servlet은 JAVA코드안에 HTML태그가 삽입되어 만들어지며 확장자는 .java이다.
서블릿 생명주기
- 사용자가 url을 호출하여 컨테이너에 새로운 요청을 한다.
- 컨테이너가 요청을 접수하여 HttpServletRequest request 객체 / HttpServletResponse response 객체를 생성
- 접수된 url을 분석하여 해당 서블릿 객체를 생성
- 서블릿 객체가 생성되면서 서블릿에서 init() 메서드를 실행하여 Servlet 객체를 초기화 한다.
- 사용자 요청을 처리하기 위해 스레드를 생성
4) service(request, response) 메서드가 호출되어, request 타입을 분석하여 타입에 따라 적절한 메서드를 호출 - GET 방식이라면 doGet() 으로, POST 방식이라면 doPost를 호출하는 식.
5) 응답을 클라이언트에 전송
6) was가 종료되면서 destory()메서드 실행, 생성된 스레드를 소멸시킨다.
간략하게
- 요청 시 서블릿 객체 생성
- 서버는 init() 메소드를 호출하여 서블릿을 초기화
- service() 메소드를 호출해서 서블릿이 브라우저의 요청을 처리
- service() 메소드는 특정 HTTP요청(GET, POST 등)을 처리하는 메소드 - doGet(), doPost() 등 - 를 호출
- 서버는 destroy()는 메소드를 호출하여 서블릿을 제거
JSP
HTML을 코딩하기 너무 어렵고 불편해서 HTML내부에 JAVA코드를 삽입하는 형식이 JSP이다. 다시말해 서블릿의 단점을 보완해서 만든 서블릿 기반의 스트립트 기술이다. 서블릿을 이용해서 웹프로그래밍을 할 수는 있지만 자바에 대한 지식이 필요하고 화면 인터페이스 구성에 너무 많은 코드들이 필요하는 등 비효율적인 측면들이 많다. 때문에 서블릿을 작성하지 않고도 웹프로그래밍을 쉽게 할 수 있게 해주는 기술이 바로 JSP(Java Server Page)이다.
Servlet과 JSP 차이 비교
Servlet
자바코드로 구현하고 컴파일, 배포한다.
HTML 태그로 문자열("")스크림으로 처리해야한다.
자바에대한 깊은 이해도를 요구한다.
코드가 수정되면 다시 컴파일하고 배포해야한다.
JSP
키워드가 태그화 되어있어 서블릿에 비해 배우기 쉽다.
자바코드를 <% %>태그 안에서 처리한다.
자바에대한 깊은 이해도가 필요하지 않다.
서블릿과 JSP는 각자 잘하는 역할을 담당해서 웹 어플리케이션을 구성한다.
JSP는 사용자에게 결과를 보여주는 역할을 담당하고, 서블릿은 클라이언트의 요청을 받아 분석하고 비즈니스 층과 통신해 처리한 후 그 결과를 다시 클라이언트에게 응답하는 컨트롤러 층을 담당한다.
한마디로, 클라이언트는 서블릿에 요청을 하고 서블릿은 이를 처리한 후 JSP를 이용해서 클라이언트에게 응답하는 구조이다.
MVC패턴에서는 View는 JSP, Controller는 Servlet을 사용한다.
지역변수, 정적변수와 전역변수의 차이
지역변수(stack 영역)
지역안에서 선언된 변수
그 영역의 닫는 중괄호 ”}” 를 만났을 때, 메모리에서 해제된다.
사용자가 직접 초기화 해야한다.
다른 영역에서 접근할 수 없기 때문에 보안성이 뛰어나다.
전역변수(data 영역)
클래스 영역 안에 있고, 전체 영역에서 사용가능한 변수
클래스 영역 외의 어떠한 영역에도 포함되어 있지 않다.
new를 만났을 때 초기화 된다.
프로그램 종료시 메모리에서 해제된다.
다른 영역에서도 접근 할 수 있기 때문에, 보안성이 상대적으로 낮다.
static변수(data 영역)
컴파일을 하게 되면 가장 먼저 메모리에 올라가고, 어떠한 경우에도 초기화가 되지 않는다.
단, 프로그램 종료시 메모리에서 해제 된다.
메모리에 고정되기 때문에 남용시 메모리 혹은 프로그램 실행 속도에 악영향을 준다.
접근제어자에 대해 설명
접근 제어자는 변수, 메서드의 접근을 제어하기 위해 적어주는 예약어를 말한다. public부터 privated, protecte, default 네 가지 종류가 있다.
public
public이 붙은 변수나 메서드는 같은 프로젝트 안에서 사용 가능하다.
default
접근 제어자가 아무것도 붙지 않은 변수나 메서드는 default 상태로, 같은 패키지 안에서만 사용 가능하다.
protected
protected가 붙은 변수나 메서드는 다른 패키지에서는 사용이 불가능하다. 다만, 상속 관계일 때는 다른 클래스에서 사용 가능하다.
private
private이 붙은 변수나 메서드는 같은 클래스 내에서만 사용 가능하다.
접근제어자 사용하는 이유
접근 제어자를 사용하는 이유는 보안 때문이라고 할 수 있다. 만약에 웹사이트에서 아이디와 비밀번호 같은 중요한 정보를 public 변수에 저장을 한다면 아무데서나 직접적으로 접근하여 그 값을 변경할 수 있기 때문에 노출되기 쉽다. 이런 중요한 변수들은 대부분 private를 붙여준다.
또한, 여러 사람들과 함께 프로그램을 만들다 보면 다른 사람이 내가 만든 중요한 변수나 메서드를 무분별하게 사용하여 값을 변경할 수 있는데, 이를 막기 위해 상황에 맞는 접근 제어자를 사용한다.
직렬화(Serialize)란?
Java 직렬화는,
자바 시스템 내부에서 사용되는 객체 또는 데이터들을 외부의 자바 시스템에서도 사용할 수 있도록 바이트(byte) 형태로 데이터 변환하는 기술과 바이트로 변환된 데이터를 다시 객체로 변환하는 역직렬화를 포함한다.
시스템적으로 JVM의 Runtim Data Area(Heap 또는 스택영역)에 상주하고 있는 객체 데이터를 바이트 형태로 변환하는 기술과 직렬화된 바이트 형태의 데이터를 객체로 변환해서 JVM으로 상주시키는 형태를 말하기도 한다.
Wrapper Class
자바의 자료형은 크게 기본 타입(primitive type)과 참조 타입(reference type)으로 나누어진다. 대표적으로 기본 타입은 char, int, float, double, boolean 등이 있고 참조 타입은 class, interface 등이 있는데 프로그래밍을 하다 보면 기본 타입의 데이터를 객체로 표현해야 하는 경우가 종종 있다. 이럴 때에 기본 자료타입(primitive type)을 객체로 다루기 위해서 사용하는 클래스들을 래퍼 클래스(wrapper class)라고 한다. 자바는 모든 기본타입(primitive type)은 값을 갖는 객체를 생성할 수 있다. 이런 객체를 포장 객체라고도 하는데 그 이유는 기본 타입의 값을 내부에 두고 포장하기 때문이다. 래퍼 클래스로 감싸고 있는 기본 타입 값은 외부에서 변경할 수 없다. 만약 값을 변경하고 싶다면 새로운 포장 객체를 만들어야 한다.
String은 래퍼클래스인데 == 비교시 값 같게 나오는 이유
연산자와 String 클래스의 equals() 메소드의 가장 큰 차이점은 연산자는 비교하고자 하는 두개의 대상의 주소값을 비교하고, String클래스의 equals() 메소드는 비교하고자 하는 두개의 대상의 값 자체를 비교한다.
int, char형 등은 Call by Value 형태로 기본적으로 대상에 주소값을 가지지 않는 형태로 사용된다.
하지만, String은 일반적인 타입이 아니라 클래스 이다. 클래스는 기본적으로 Call by Reference형태로 생성 시 주소값이 부여된다. 그렇기에 String 타입을 선언했을 때는 같은 값을 부여하더라도 서로간의 주소값이 다를 수가 있다.
제네릭이란?
‘데이터 형식에 의존하지 않고, 하나의 값이 여러 다른 데이터 타입들을 가질 수 있도록 하는 방법’
만약에 우리가 어떤 자료구조를 만들어 배포하려고 한다. 그런데 String 타입도 지원하고싶고 Integer타입도 지원하고 싶고 많은 타입을 지원하고 싶다. 그러면 String에 대한 클래스, Integer에 대한 클래스 등 하나하나 타입에 따라 만들 것인가? 그건 너무 비효율적이다. 이러한 문제를 해결하기 위해 우리는 제네릭이라는 것을 사용한다.
이렇듯 제네릭(Generic)은 클래스 내부에서 지정하는 것이 아닌 외부에서 사용자에 의해 지정되는 것을 의미한다. 한마디로 특정(Specific) 타입을 미리 지정해주는 것이 아닌 필요에 의해 지정할 수 있도록 하는 일반(Generic) 타입이라는 것이다.
Generic(제네릭)의 장점
- 제네릭을 사용하면 잘못된 타입이 들어올 수 있는 것을 컴파일 단계에서 방지할 수 있다.
- 클래스 외부에서 타입을 지정해주기 때문에 따로 타입을 체크하고 변환해줄 필요가 없다. 즉, 관리하기가 편하다.
- 비슷한 기능을 지원하는 경우 코드의 재사용성이 높아진다.
final이란?
final은 한 번만 할당할 수 있는 엔티티를 정의할 때 사용한다.
메서드를 final로 선언하면 상속받은 클래스에서 오버라이딩이 불가능하게 되고 구현한 코드의 변경을 원하지 않을 때 사용한다. side-effect가 있으면 안 되는 자바 코어 라이브러리에서 final로 선언된 부분을 많이 찾을 수 있다.
자바 버전
자바 8 특징
- 람다 표현식
함수형 프로그래밍을 자바에서 사용 가능하게 해준다.
별도로 함수를 구현하지 않고 화살표를 사용해서 간단히 한 줄로 함수를 만들 수 있다. - Stream
반복문을 처리하는 방법 중 하나로, 병렬처리가 가능하다.
예로, 스레드 풀에 가용할 수 있는 스레드들을 가져와서 사용함으로 반복문 처리 속도가 빠르다. - interface의 default라는 메소드를 구현할 수 있음
기존에는 공통적인 함수라도 인터페이스의 구현체들은 똑같은 것을 각각 다 따로따로 구현을 해줘야 했는데, default가 생김으로써 인터페이스안에 공통적으로 사용하는 함수를 미리 정의할 수 있게 되었다. - Optional
Null이 될 수 있는 객체를 감싸는 래퍼클래스이다.
객체에 null이 대입되어 발생되는 오류들이 많아서, 이를 좀 더 안전하게 처리하기 위해 만들어졌다.
자바 11 특징
- String, File 클래스에 몇 가지 메소드 추가
- 람다표현식에 var 키워드 사용 가능하도록 기능 추가
- Http Client 추가
기존에는 아파치 라이브러리를 사용했는데, 11부터는 자바 표준 Http Client API가 생겼고, 성능이 이전 것보다 개선되었다.
스프링이란?
자바의 오픈소스 애플리케이션 프레임워크 중 하나로, 스프링의 기본철학은 특정 기술에 종속되지 않고 객체를 관리할 수 있는 프레임워크를 제공하는 것이다. 그래서 컨테이너로 자바 객체를 관리하면서 의존성 주입과 제어의 역전을 통해 결합도를 낮추게 된다.
IoC란?
IoC는 Inversion of Control의 약자로 제어의 역전을 의미한다. 제어권이 사용자에게 있지 않고, 프레임워크에 있어서 필요에 따라 사용자의 코드를 호출하게 된다. 스프링에서는 인스턴스의 생성부터 소멸까지 개발자가 아닌 컨테이너에서 대신 관리하게 된다.
DI란?
DI는 Dependency Injection의 약자로, 의존성 주입을 의미한다. 객체간의 의존관계를 미리 설정해두면 스프링 컨테이너가 의존관계를 자동으로 연결해준다. 이렇게 되면 직접 의존하는 객체를 생성하거나 검색해서 가져올 필요없어서 결합도가 낮아지는 장점이 있다.
디스패처 서블릿이란?
디스패처 서블릿의 dispatch는 “보내다”라는 뜻을 가지고 있다. 그리고 이러한 단어를 포함하는 디스패처 서블릿은 HTTP 프로토콜로 들어오는 모든 요청을 가장 먼저 받아 적합한 컨트롤러에 위임해주는 프론트 컨트롤러(Front Controller)라고 정의할 수 있다.
이것을 보다 자세히 설명하자면, 클라이언트로부터 어떠한 요청이 오면 Tomcat(톰캣)과 같은 서블릿 컨테이너가 요청을 받게 된다. 그리고 이 모든 요청을 프론트 컨트롤러인 디스패처 서블릿이 가장 먼저 받게 된다. 그러면 디스패처 서블릿은 공통적인 작업을 먼저 처리한 후에 해당 요청을 처리해야 하는 컨트롤러를 찾아서 작업을 위임한다.
여기서 Front Controller(프론트 컨트롤러)라는 용어가 사용되는데, Front Controller는 주로 서블릿 컨테이너의 제일 앞에서 서버로 들어오는 클라이언트의 모든 요청을 받아서 처리해주는 컨트롤러로써, MVC 구조에서 함께 사용되는 디자인 패턴이다.
디스패처 서블릿으로 인한 web.xml 역할 축소
Spring MVC는 Dispatcher-Servlet의 사용으로 web.xml의 역할을 축소시켜준다. 기존에는 모든 서블릿에 대해 URL 매핑을 활용하기 위해서 web.xml에 모두 등록해주어야 했지만, dispatcher-servlet이 해당 어플리케이션으로 들어오는 모든 요청을 처리해주면서 작업이 상당히 편리해졌다.
AOP란?
Aspect-Oriented Programming의 약자이다.
흩어진 Aspect들을 모아서 모듈화 하는 기법이다.
서로 다른 클래스라고 하더라도 비슷한 기능을 하는 부분(ex 비슷한 메서드, 비슷한 코드)이있다. 이 부분을 Concern이라고 한다.
이 때 만약 노란색 기능을 수정하여야하면, 각각 클래스의 노란색 기능을 수정해주어야 하기 때문에, 유지 보수 면에서 불리하다.
이것을 해결한 방법이 AOP이다.
흩어진 기능들을 모을 때 사용하는 것이 Aspect이다. 각각 Concern 별로 Aspect를 만들어주고, 어느 클래스에서 사용하는 지 입력해주는 방식이다.
AOP 용어 설명
aspect
Advice(부가기능) + PointCut(advice를 어디에 적용시킬 것인지 결정)
AOP의 기본 모듈이다.
핵심기능 코드 사이에 침투된 부가기능을 독립적인 aspect로 구분해 낼수 있다.
구분된 부가기능 aspect를 런타임 시에 필요한 위치에 동적으로 참여하게 할 수 있다.
싱글톤 형태의 객체로 존재한다.
Target
핵심 기능을 담고 있는 모듈로 타겟은 부가기능을 부여할 대상이 된다.
Advice
타겟에 제공할 부가기능을 담고 있는 모듈
Join Point
어드바이스가 적용될 수 있는 위치
Pointcut
어드바이스를 적용할 타겟의 메서드를 선별하는 정규표현식이다.
포인트컷 표현식은 execution으로 시작하고 메서드의 Signature를 비교하는 방법을 주로 이용한다.
Weaving
포인트컷에 의해서 결정된 타겟의 조인 포인트에 부가기능(advice)를 삽입하는 과정을 뜻한다.
AOP가 핵심기능(타겟)의 코드에 영향을 주지 않으면서 필요한 부가기능(advice)를 추가할 수 있도록 해주는 핵심적인 처리과정이다.
필터와 인터셉트 차이
필터(Filter)는,
J2EE 표준 스펙 기능으로 디스패처 서블릿(Dispatcher Servlet)에 요청이 전달되기 전/후에 url 패턴에 맞는 모든 요청에 대해 부가작업을 처리할 수 있는 기능을 제공한다. 디스패처 서블릿은 스프링의 가장 앞단에 존재하는 프론트 컨트롤러이므로, 필터는 스프링 범위 밖에서 처리가 되는 것이다.
즉, 스프링 컨테이너가 아닌 톰캣과 같은 웹 컨테이너에 의해 관리가 되는 것이고(스프링 빈으로 등록은 된다), 디스패처 서블릿 전/후에 처리하는 것이다.
인터셉터(Interceptor)는,
J2EE 표준 스펙인 필터(Filter)와 달리 Spring이 제공하는 기술로써, 디스패처 서블릿(Dispatcher Servlet)이 컨트롤러를 호출하기 전과 후에 요청과 응답을 참조하거나 가공할 수 있는 기능을 제공한다. 즉, 웹 컨테이너에서 동작하는 필터와 달리 인터셉터는 스프링 컨텍스트에서 동작을 하는 것이다.
디스패처 서블릿은 핸들러 매핑을 통해 적절한 컨트롤러를 찾도록 요청하는데, 그 결과로 실행 체인(HandlerExecutionChain)을 돌려준다. 그래서 이 실행 체인은 1개 이상의 인터셉터가 등록되어 있다면 순차적으로 인터셉터들을 거쳐 컨트롤러가 실행되도록 하고, 인터셉터가 없다면 바로 컨트롤러를 실행한다.
필터(Filter) vs 인터셉터(Interceptor) 차이 정리 및 요약
| 대상 | 필터(Filter) | 인터셉터(Interceptor |
|---|---|---|
| 관리되는 컨테이너 | 웹 컨테이너 | 스프링 컨테이너 |
| Request/Response 객체 조작 가능 여부 | O | X |
| 용도 | 공통된 보안 및 인증/인가 관련 작업 | 세부적인 보안 및 인증/인가 공통 작업 |
| 모든 요청에 대한 로깅 또는 검사 | API 호출에 대한 로깅 또는 감사 | |
| 이미지/데이터 압축 및 문자열 인코딩 | Controller로 넘겨주는 정보(데이터)의 가공 | |
| Spring과 분리되어야 하는 기능 |
일부에서 필터(Filter)가 스프링 빈으로 등록되지 못하며, 빈을 주입 받을 수도 없다고 하는데, 이는 잘못된 설명이다. 이는 매우 옛날의 이야기이며, 필터는 현재 스프링 빈으로 등록이 가능하며, 다른 곳에 주입되거나 다른 빈을 주입받을 수도 있다.
스프링 MVC 구조 흐름
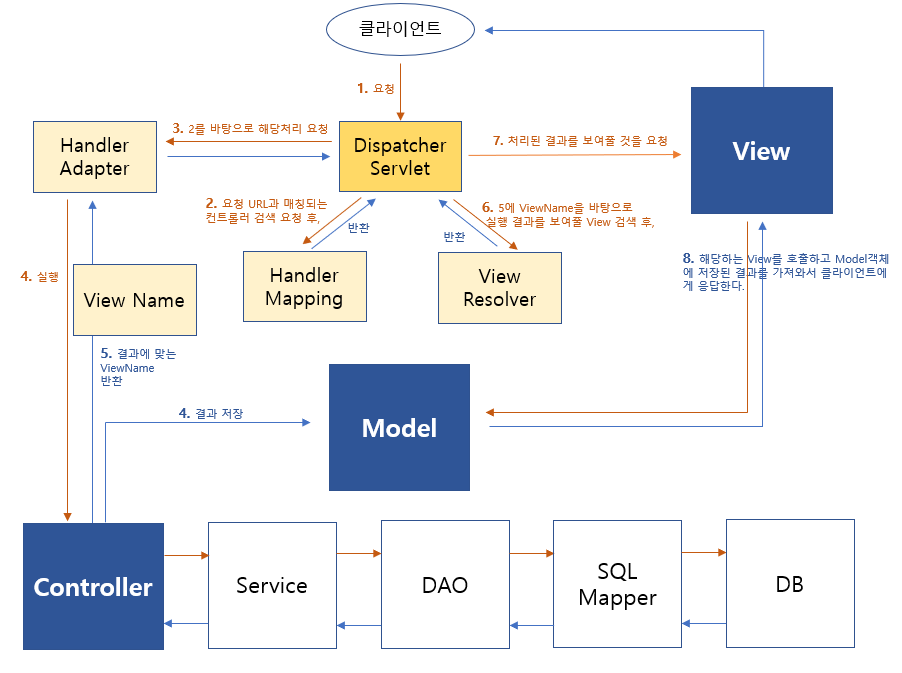
DispatcherServlet
web.xml에 정의되어 있으며, sevlet-context.xml 설정 파일을 읽어 구동한다.
Front Controller라고도 한다.
클라이언트의 모든 Request를 받아 제어한다.
Controller에 요청을 전달하고 결과값을 View에 전달한다.
HandlerMapping
요청 URL에 매핑되는 Controller를 찾아 DispatcherServlet에 반환한다.
HandlerAdapter
HandlerMapping을 통해 받은 Controller에 맞는 메서드를 탐색한다.
Controller
클라이언트의 요청을 처리한 후, 비지니스 로직과 서비스를 처리하여 View에 전달할 객체를 Model에 저장한다.
View Name
Controller의 처리 후, View에 해당하는 View Name을 저장하여 반환한다.
Model
Controller에서 처리 후, View에 전달할 객체를 저장하는 곳.
View Resolver
Controller가 반환한 View Name을 기반으로 맞는 View를 찾아 DispatcherServlet에 반환한다.
View
DispatcherServlet이 전달한 View를 호출하고, Model객체에서 필요한 객체를 가져와 클라이언트에 응답한다.
스프링과 스프링 부트 차이
스프링 프레임워크(Spring Framework)는, 자바 플랫폼을 위한 오픈소스 애플리케이션 프레임워크로서 간단히 스프링(Spring)이라고도 불린다. 동적인 웹 사이트를 개발하기 위한 여러 가지 서비스를 제공하고 있다.
스프링 프레임워크는, 기능이 많은만큼 환경설정이 복잡한 편이다. 이에 어려움을 느끼는 사용자들을 위해 나온 것이 바로 스프링 부트다. 스프링 부트는 스프링 프레임워크를 사용하기 위한 설정의 많은 부분을 자동화하여 사용자가 정말 편하게 스프링을 활용할 수 있도록 돕는다. 스프링 부트 starter 디펜던시만 추가해주면 바로 API를 정의하고, 내장된 탐캣이나 제티로 웹 애플리케이션 서버를 실행할 수 있다. 심지어 스프링 홈페이지의 이니셜라이저를 사용하면 바로 실행 가능한 코드를 만들어준다. 실행환경이나 의존성 관리 등의 인프라 관련 등은 신경쓸 필요 없이 바로 코딩을 시작하면 된다. 그리고 바로 그것이 스프링의 키 포인트이다.
Spring Boot는 Spring framework와 몇 가지면에서 차이가 있다.
Embed Tomcat을 사용하기 때문에, (Spring Boot 내부에 Tomcat이 포함되어있다.) 따로 Tomcat을 설치하거나 매번 버전을 관리해 주어야 하는 수고로움을 덜어준다.
starter을 통한 dependency 자동화 :
아마 Spring 유저들이 가장 열광한 기능이 아닐까 싶다. 과거 Spring framework에서는 각각의 dependency들의 호환되는 버전을 일일이 맞추어 주어야 했고, 때문에 하나의 버전을 올리고자 하면 다른 dependeny에 까지 영향을 미쳐 version관리에 어려움이 많았다. 하지만, 이제 starter가 대부분의 dependency를 관리해주기 때문에 이러한 걱정을 많이 덜게 되었다.
XML설정을 하지 않아도 된다.
jar file을 이용해 자바 옵션만으로 손쉽게 배포가 가능하다.
Spring Actuaor를 이용한 애플리케이션의 모니터링과 관리를 제공한다.
스프링 어노테이션
Annotation은 클래스와 메서드에 추가하여 다양한 기능을 부여하는 역할을 한다. Annotation을 활용하여 Spring Framework는 해당 클래스가 어떤 역할인지 정하기도 하고, Bean을 주입하기도 하며, 자동으로 getter나 setter를 생성하기도 한다. 특별한 의미를 부여하거나 기능을 부여하는 등 다양한 역할을 수행할 수 있다.
Spring의 대표적인 Annotation
@Component
개발자가 생성한 Class를 Spring의 Bean으로 등록할 때 사용하는 Annotation이다. Spring은 해당 Annotation을 보고 Spring의 Bean으로 등록한다.
@ComponentScan
Spring Framework는 @Component, @Service, @Repository, @Controller, @Configuration 중 1개라도 등록된 클래스를 찾으면, Context에 bean으로 등록한다. @ComponentScan Annotation이 있는 클래스의 하위 Bean을 등록 될 클래스들을 스캔하여 Bean으로 등록해준다.
@Bean
@Bean Annotation은 개발자가 제어가 불가능한 외부 라이브러리와 같은 것들을 Bean으로 만들 때 사용한다.
@Controller
Spring에게 해당 Class가 Controller의 역할을 한다고 명시하기 위해 사용하는 Annotation이다.
@RequestHeader
Request의 header값을 가져올 수 있으며, 해당 Annotation을 쓴 메소드의 파라미터에 사용한다.
@RequestMapping
@RequestMapping(value=”“)와 같은 형태로 작성하며, 요청 들어온 URI의 요청과 Annotation value 값이 일치하면 해당 클래스나 메소드가 실행된다. Controller 객체 안의 메서드와 클래스에 적용 가능하다.
@RequestParam
URL에 전달되는 파라미터를 메소드의 인자와 매칭시켜, 파라미터를 받아서 처리할 수 있는 Annotation으로 아래와 같이 사용한다. Json 형식의 Body를 MessageConverter를 통해 Java 객체로 변환시킨다.
@ModelAttribute
클라이언트가 전송하는 HTTP parameter, Body 내용을 Setter 함수를 통해 1:1로 객체에 데이터를 연결(바인딩)한다. RequestBody와 다르게 HTTP Body 내용은 multipart/form-data 형태를 요구한다. @RequestBody가 json을 받는 것과 달리 @ModelAttribute 의 경우에는 json을 받아 처리할 수 없다.
@ResponseBody
@ResponseBody은 메소드에서 리턴되는 값이 View 로 출력되지 않고 HTTP Response Body에 직접 쓰여지게 된다. return 시에 json, xml과 같은 데이터를 return 한다.
@Autowired
Spring Framework에서 Bean 객체를 주입받기 위한 방법은 크게 아래의 3가지가 있습니다. Bean을 주입받기 위하여 @Autowired 를 사용한다. Spring Framework가 Class를 보고 Type에 맞게(Type을 먼저 확인 후, 없으면 Name 확인) Bean을 주입한다.
@Autowired
생성자 (@AllArgsConstructor 사용)
setter
@GetMapping
RequestMapping(Method=RequestMethod.GET)과 똑같은 역할을 한다.
@PostMapping
RequestMapping(Method=RequestMethod.POST)과 똑같은 역할을 한다.
@SpringBootTest
Spring Boot Test에 필요한 의존성을 제공해준다.
@Test
JUnit에서 테스트 할 대상을 표시한다.
Lombok의 대표적인 Annotation과 역할
@Setter
Class 모든 필드의 Setter method를 생성해준다.
@Getter
Class 모든 필드의 Getter method를 생성해준다.
@AllArgsConstructor
Class 모든 필드 값을 파라미터로 받는 생성자를 추가한다.
@NoArgsConstructor
Class 기본 생성자를 자동으로 추가해준다.
@ToString
Class 모든 필드의 toString method를 생성한다.
스프링 버전별 기능
Spring 3.0
Spring3.0 부터 Java5가 지원된다. 기존에 유지하던 하위호환성에 Generic 이나 가변인자(varargs) 등과 같은 개선사항이 추가된다.
전체 프레임워크를 하나의 spring.jar 파일로 제공하던 부분을 여러개의 jar 파일로 나누어 제공한다.
SPEL(Spring Expression Language)가 도입되었다. c) Rest API 에 대한 지원이 추가되었다.
OXM(Object Xml Mapping) 기능이 추가되어 설정을 Xml 형태로 할 수 있게 지원한다. ex) Java annotation 을 이용해서 DI 의 지원이 가능하다.
Spring 4.0
Spring 3.0 이 Java5+ 버전들에 대해 지원을 한다면 Spring 4.0 버전은 Java 8 의 특징들을 적용할 수 있게 지원한다.
Starter Pack 이 생겨서 초보 개발자들에게 큰 진입장벽인 POM 설정을 도와준다.
기존에 사용하지 않지만 호환성을 위해 남겨져있던 Deprecated Package 들이 제거되었으며 Hibernate 3.6 이상, EhCache 2.1 이상, Groovy 1.8 이상, Joda-Time 2.0 이상 등 새로운 Dependency 들에 대해 지원한다.
Java6, Java7, Java8 의 고유 기능들에 대해 지원한다. 람다식, Optional, Callback Interface 등의 기능을 Spring framework 레벨에서 사용할 수 있다.
Java EE 6, 7 에 대해 고려되어 있다. JPA 2.0 과 Servlet 3.0 에 대한 지원이 포함되어 있다는 뜻이다.
Groovy 를 이용한 Bean 설정이 가능하다. 자세한 사용법은 GroovyBeanDefinitionReader 문서를 참조하자.
Core 컨테이너들의 기능 지원이 확대되있다. 먼저 Repository 들이 좀 더 쉽게 Inject 될 수 있으며, 각종 Metadata Annotation 들을 이용한 Custom Annotation 작성이 가능하다. @Lazy 를 이용한 Lazy Injection 이나 @Order 을 통한 Ordered Interface, @Profile 을 통한 프로필 버전 관리가 쉬워졌다.
Web 을 개발하기 위한 도구들이 생겼다. @RestController 같은 것들이 그것이다.
Web Socket 이나 STOMP 등의 프로토콜을 같이 지원한다.
테스트 환경이 개선되었다. Framework 레벨에서 Mock 을 위한 ServletContext 를 별도로 지원한다.
Spring 5.0
Spring 5.0 은 JDK 8+, 9 등에 대해서 지원하며 Java8을 표준으로 사용한다.
코어로직에 있어서 JDK 8의 특징들이 강화되었다.
HTTP 메시지 코덱의 XML과 JSON 지원에 대한 구현이 Encoder 와 Decoder 의 사용을 통해 추상화 되었다.
웹에 대한 지원이 향상되었다. 특히 Protobuf 3.0 지원이 적용되었다.
MVC 1과 MVC 2의 차이
MVC1
웹브라우저 요청을 JSP가 처리, JSP가 Controller와 view 기능 모두 담당한다.
쉽게 말씀드리면, 하나의 jsp페이지 내에서 controller는 자바, view는 html, css 이벤트는 자바스크립트를 사용한다.
Model은 jdbc 인터페이스로 DB 조작하면서 class를 정의한다.
장점
페이지 흐름이 단순하고 구조가 간단하여 중소형 프로젝트에 적합하다.
단점
유지보수가 어려워서 웹 규모가 커질수록 복잡해진다.
개발자와 디자이너 역할 분담이 어려워서 원할한 의사소통이 필수이다.
규모가 작고 유지보수 적은 경우 채택이 필요하다.
MVC2
웹 브라우저 요청을 controller에서 처리한다.
controller는 요청에 대한 로직처리를 model로 보내고, model은 결과를 view로 보내여 사용자에게 응답하게 된다.
model은 mvc1, mvc2 모두 동일하다.
view는 jsp로 구성되어 있으며, 자바는 포함되지 않고 jstl을 사용해 결과를 표현한다.
장점
유지보수, 확장에 용이하며 controller와 view의 분리로 명료한 구조를 가진다.
개발자와 디자이너 역할 분담이 한다.
단점
구조 설계를 위한 시간이 많이 소요되어 개발이 어렵다.
높은 수준의 이해도가 필요하여 개발팀 팀원의 수준이 높아야 한다.
규모가 크고 유지보수 많은 경우 채택 필요하다.
ORM
ORM은 Object Relational Mapping의 약자로, 관계형 데이터베이스를 OOP언어로 변환해주는 기술이다. 그래서 비즈니스 코드가 DB 테이블에 바로 접근하게 도와준다.
JPA
JPA는 ORM을 위해 자바에서 제공하는 API이다. 자바 객체와 DB 테이블을 매핑하는데요. 구현체로는 하이버네이트가 있다.
ORM, JPA, Hibernate 장단점
장점으로는, 비즈니스 로직에 집중하고 객체중심의 개발을 할 수 있게 된다. 그리고 메소드를 호출하는 것만으로 쿼리를 수행해서 생산성이 향상되고, 유지보수 비용이 줄어든다. 그리고 특정 DB에 의존하지 않게 된다.
하지만 단점으로는, 직접 SQL을 호출하는 것보다는 조금 느리구요. 그리고 복잡한 쿼리같은 것은 메소드로 처리가 힘들다.
Mybatis란?
객체 지향 언어인 자바의 관계형 데이터베이스 프로그래밍을 좀더 쉽게 할 수 있게 도와주는 개발 프레임워크로써 JDBC를 통해 데이터베이스에 엑세스하는 작업을 캡슐화하고 일반 SQL 쿼리, 저장 프로 시저 및 고급 매핑을 지원하며 모든 JDBC 코드 및 매개 변수의 중복작업을 제거한다. MyBatis에서는 프로그램에 있는 SQL쿼리들을 한 구성파일에 구성하여 프로그램 코드와 SQL을 분리할 수 있는 장점을 가지고 있다.
요약
자바의 관계형 데이터베이스 프로그래밍을 좀더 쉽게 만들어주는 개발 프레임워크이고 SQL쿼리문과 프로그램 코드를 분리할수 있다는 장점을 가진다.
Mybatis, JPA 차이
JPA(ORM)
장점
- RDB에 종류와 관계없이 사용 가능하다. 추후 DB 변경이나 코드 재활용에 용이하다.
- 기본적인 CRUD 제공과 페이징 처리 등 상당 부분 구현되어 있어 비지니스 로직에 집중할 수 있다.
- 테이블 생성, 변경 등 엔티티 관리가 간편하다.
- 쿼리에 집중할 필요 없어 빠른 개발이 가능하다.
SQL을 몰라도 된다는 뜻은 아니다. JPA는 SQL을 잘할수록 훨씬 더 잘 사용할 수 있다.
위 말의 뜻은 select * from user 같은 쿼리를 직접 작성할 필요 없이 Java 코드로 간편하게 사용할수 있다는 뜻
단점
- 어렵다.
: 단방향, 양방향, 임베디드 관계 등 이해해야할 내용이 많으며, 연관관계 이해 없이 잘못 코딩 했을 시 성능상의 문제와 동작이 원하는대로 되지 않는 일이 발생한다.
ex) Board 엔티티에 List의 형태로 Reply 엔티티가 있을 시, 단방향 연관관계인 경우 하나의 reply가 변경되어도 모두 삭제되고 다시 전부 insert되는 경우
하나의 Board 조회 시 reply를 Join이 아닌 여러개의 select문으로 하나하나 읽어오는 문제
MyBatis(SQL Mapper)
장점
- JPA에 비해 쉽다.
: SQL 쿼리를 그대로 사용하기에 복잡한 Join, 튜닝 등을 좀더 수월하게 작성 가능하다. - SQL의 세부적인 내용 변경 시 좀 더 간편하다.
- 동적 쿼리 사용 시 JPA보다 간편하게 구현 가능하다.
단점
- 데이터 베이스 설정 변경 시 수정할 부분이 너무 많다. (Oracle의 페이징 쿼리를 MySQL에서 사용 불가능!)
- Mapper작성부터 인터페이스 설계까지 JPA보다 많은 설계와 파일, 로직이 필요하다.
- 특정 DB에 종속적이다.
Spring JDBC
Spring JDBC는 JDBC의 모든 저수준 처리를 스프링 프레임워크에 위임하므로써, Connection 연결 객체 생성 및 종료, Statement 준비/실행 및 종료, ResultSet 처리 및 종료, 예외 처리, 트랙잭션 등의 반복되는 처리를 개발자가 직접하지 않고 Database에 대한 작업을 수행할 수 있다.
SQL Query 수행하기 위해 필요한 저수준 작업을 내부적으로 처리해주고 보다 추상적인 기능을 제공하는JdbcTemplate, SimpleJdbcInsert, NamedParameterJdbcTemplate 객체와 Helper 객체(RowMapper) 등을 포함한다.
따라서,
JdbcTemplate 등의 객체를 이용하면 Connection 연결/종료와 같은 세부적인 작업을 직접 처리하지 않아도 된다.
또한,
JDBC에서 발생하는 에러는 Runtime Exception이다. 따라서, 이를 일반 예외(Exception)로 감싸 처리해주어야 하는데 Spring JDBC는 이를 내부적으로 커스텀한 일반 예외로 변환해 전파해준다.
DAO, DTO, VO 란?
DAO(Data Access Object)
데이터 사용기능 담당하는 클래스이다. DB 데이터 조회나 수정, 입력, 삭제와 같은 로직을 처리하기 위해 사용한다. DAOInterface/DAOImplement 로 구분지어 명세와 구현 분리하며 개발한다. 만약 Mybatis연동 때처럼 Interface만 필요한 경우 그냥 DAO라고 명시할 수 있다.
DTO(Data Transfer Object)
데이터 저장 담당 클래스이다. Controller, Service, View처럼 계층 간의 데이터 교환을 위해 쓴다. 로직을 갖고 있지 않으며 순수한 데이터 객체이며 getter, setter 메소드만을 갖고 있다.
VO(Value Object)
값 오브젝트로써 값을 위해 쓴다. read-Only 특징(사용하는 도중에 변경 불가능하며 오직 읽기만 가능)을 가진다. DTO와 유사하지만 DTO는 setter를 가지고 있어 값이 변할 수 있다.
프레임워크의 특징과 프레임워크와 라이브러리 차이점
Framework란 소프트웨어 환경에서 복잡한 문제를 해결하거나 서술하는데 사용되는 기본 개념 구조이다. 뼈대가 되는 부분을 미리 구현한 클래스, 인터페이스 , 메소드 등의 모음이라고 할 수 있다. 프레임워크는 설계자가 의도한 여러 디자인 패턴으로 구성되어 있다. 따라서 개발자가 에플리케이션의 구조적 설계를 신경 쓸 필요가 없다. 또한 일정 수준 이상의 품질을 보증하는 코드를 비교적 빠르고 편하게 완성 및 유지보수할 수 있는 솔루션이라고 할 수 있다.
라이브러리와 프레임워크는 애플리케이션의 틀과 구조를 결정한다는 측면에서 활용도가 상당히 유사하나 라이브러리는 특정 기능이 필요할 때 호출해서 쓰는 도구 모음이다. 프레임워크가 큰 뼈대는 이미 잡혀있고 그 안의 내용물을 채우는 느낌이라면 라이브러리는 개발자가 호출해서 능동적으로 사용하는 것이라고 볼 수 있다. 즉, 프레임워크는 꼭 써야되는 것과 지켜야되는 룰이 있는 반면 라이브러리는 쓰든 안쓰든 개발자 마음대로 할 수 있다는 점에서 차이가 있다.
Spring Framework
자바(JAVA) 플랫폼을 위한 오픈소스 애플리케이션 프레임워크
자바 엔터프라이즈 개발을 편하게 해주는 오픈소스 경량급 애플리케이션 프레임워크
자바 개발을 위한 프레임워크로 종속 객체를 생성해주고, 조립해주는 기구
자바로 된 프레임워크로 JavaSE로 된 자바 객체(POJO)를 JavaEE에 의존적이지 않게 연결해주는 역할
특징
크기와 부하의 측면에서 경량
제어 역행(IOC)이라는 기술을 통해 애플리케이션의 느슨한 결합을 도모.
관점 지향 프로그래밍(AOP)을 위한 풍부한 자원
애플리케이션 객체의 생명주기와 설정을 포함하고 관리한다는 점에서 일종의 컨테이너라고 할 수 있음
간단한 컴포넌트로 복잡한 애플리케이션을 구성하고 설정할 수 있음
Spring AOP가 무엇인지 OOP와 AOP를 비교하여 설명하시오.
AOP는 Aspect Oriented Programming의 약자로, 관점 지향 프로그래밍이라고 한다. 애플리케이션의 핵심적인 기능과 부가적인 기능을 분리해 Aspect라는 모듈로 만들어 설계하고 개발하는 방법이다. OOP는 Object Oriented Programming의 약자로 객체 지향 프로그래밍이라고 한다. OOP와 AOP는 서로 상반되는 개념은 아니며 오히려 OOP를 더욱 OOP답게 사용할 수 있도록 하는 것이 AOP이다.
공통적 기능을 모든 모듈에 적용하기 위한 방법으로 상속을 이용하는데 Java에서는 다중 상속이 불가능하다. 그리고 기능 구현 부분에서 핵심 코드와 공통 기능 코드가 섞여있어서 보기에도 불편하고, 효율성이 떨어집니다. 이러한 이유로 AOP가 등장했다.
Aspect - 공통 기능 / Advice와 Pointcut을 합친 개념
Advice - Aspect의 기능 자체 / 무엇을 삽입할 것인가? / 부가적인 기능(횡단적 관심)을 정의한 코드
Joinpoint - Advice를 적용해야 하는 부분. 즉, 어떤 시점에 삽입할 것인지에 대한 특정 위치.
- before : 메소드 실행 전
- after : 메소드 실행 후
- AfterReturning : 반환된 후
- AfterThrowing : 예외가 던져지는 시점
- around : 메소드 실행 전, 후
Pointcut - Joinpoint의 부분으로 실제 Advice가 적용된 부분 / 어떤 클래스의 어떤 메소드에 어느 joinpoint를 사용할 것인가?
Weaving - Advice를 핵심기능에 적용하는 행위 / AOP가 기존의 핵심 관심 모듈의 코드에 전혀 영향을 주지 않으면서 필요한 횡단 관심 기능을 추가할 수 있게 해주는 핵심적인 처리 과정.
Proxy - Client와 Target 사이에 존재하면서 부가기능을 제공하는 object / Aspect가 곧바로 핵심 기능에서 실행되는 것이 아니라, proxy(대행자)에서 공통 기능이 수행하도록 하는 것.
브라우저에서 URL치면 발생하는 일
브라우저에 maps.google.com을 입력했을 때 일어나는 일들을 여덟 단계로 정리할 수 있다.
브라우저 주소창에 maps.google.com을 입력한다.
브라우저가 maps.google.com의 IP 주소를 찾기 위해 캐시에서 DNS 기록을 확인한다.
만약 요청한 URL(maps.google.com)이 캐시에 없다면, ISP의 DNS 서버가 DNS 쿼리로 maps.google.com을 호스팅하는 서버의 IP 주소를 찾는다.
브라우저가 해당 서버와 TCP 연결을 시작한다.
브라우저가 웹서버에 HTTP 요청을 보낸다.
서버가 요청을 처리하고 응답을 보낸다.
서버가 HTTP 응답을 보낸다.
브라우저가 HTML 컨텐츠를 보여준다.
쿠키, 세션, 토큰
쿠키,
쿠키는 클라이언트 로컬에 저장되는 키 / 값이 포함된 데이터 파일이다.
인증 유효시간을 명시할 수 있으며, 유효시간 동안은 브라우저가 종료되어도 인증이 유지된다.
쿠키는 클라이언트의 상태 정보를 로컬에 저장하고, 저장한 내용을 참조한다.
클라이언트에 300개까지 쿠키 저장이 가능하며, 도메인당 20개의 값을 가질 수 있다. 하나의 쿠키값은 4KB까지 저장할 수 있다.
Response Header에 Set-Cookie 속성을 사용하면 클라이언트에 쿠키를 만들 수 있다.
쿠키는 따로 요청하지 않아도 브라우저가 Request시에 Request Header를 넣어서 자동으로 서버에 전송한다.
동작 방식
- 클라이언트가 페이지 요청
- 서버에서 쿠키를 생성
- HTTP 헤더에 쿠키를 포함시켜 응답
- 브라우저가 종료되어도 쿠키 유효시간동안 클라이언트에서 보관
- 같은 요청 시 HTTP 헤더에 쿠키를 함께 전송
- 이전 상태 정보를 변경 할 필요가 있다면, 쿠키를 업데이트 하여 변경된 쿠키를 HTTP 헤더에 포함시켜 응답
세션 개념 및 동작방식
세션,
세션은 쿠키를 기반하고 있지만, 사용자 정보를 브라우저에 저장하는 쿠키와 달리 세션은 서버 측에서 관리한다.
서버에서 클라이언트를 구분하기 위해 세션 ID를 부여하며, 브라우저가 서버에 접속해서 종료될 때까지 인증상태를 유지한다.
접속 시간에 제한을 두어 일정 시간 응답이 없으면 정보가 유지되지 않게 설정도 가능하다.
사용자 정보를 서버에 두기 때문에 쿠키보다 보안에는 좋지만, 사용자가 많아질수록 서버 메모리를 많이 차지하게 된다.
동접자 수가 많은 웹 사이트인 경우, 서버에 과부하를 주게 됨으로 성능 저하의 원인이 된다.
클라이언트 Request를 보내면, 서버의 엔진이 클라이언트에게 유일한 ID를 부여한다. 이 ID가 세션ID이다.
동작 방식
- 클라이언트가 서버에 접속 시 세션 ID를 발급 받음
- 클라이언트는 세션 ID에 대해 쿠키를 사용해서 저장하고 가지고 있음
- 클라리언트는 서버에 요청할 때, 이 쿠키의 세션 ID를 같이 서버에 전달해서 요청
- 서버는 세션 ID를 전달 받아서 별다른 작업없이 세션 ID로 세션에 있는 클라언트 정보를 가져와서 사용
- 클라이언트 정보를 가지고 서버 요청을 처리하여 클라이언트에게 응답
쿠키와 세션
쿠키와 세션은 비슷하다. 그 이유는 세션도 결국 쿠키를 사용하기 때문이다.
가장 큰 차치점은 사용자의 정보가 저장되는 위치이다. [ 쿠키 : 클라이언트(로컬) | 세션 : 서버 ]
보안 면에서는 세션이 쿠키보다 우수하지만 요청 속도는 세션보다 쿠키가 더 빠릅니다. (세션은 서버의 처리가 필요)
사용자 정보 저장 위치
쿠키 : 클라이언트 (로컬)
세션 : 서버
보안
쿠키 : 쿠키는 로컬에 저장되기 때문에 변질되거나 request에서 스니핑 당할 우려가 있어 보안에 취약한다.
세션 : 세션은 쿠키를 이용해서 세션ID만 저장하고 그것으로 구분해서 서버에서 처리하기 때문에 비교적 보안성이 좋다.
유효시간
쿠키 : 유효시간이 있고 파일로 저장되기 때문에 쿠키를 삭제하지 않는 이상 브라우저가 종료되도 유효시간까지 정보가 남아 있을 수 있다. (로컬에서 관리)
세션 : 세션도 유효시간을 설정할 수는 있지만, 브라우저가 종료되면 설정된 유효시간이 만료되지 않았더라도 삭제된다. (서버에서 관리)
속도
쿠키 : 쿠키파일에 정보가 있기 때문에 서버에 요청시 속도가 빠르다.
세션 : 정보가 서버에 있기 때문에 처리가 요구되어 비교적 느린 속도를 가진다.
토큰
토큰,
유저가 인증에 성공하면 서버는 토큰을 생성해서 클라이언트로 전달한다.
토큰과 세션의 방식을 비슷한데 차이가 있다.
세션 인증에서는 서버가 세션ID를 저장하고 클라이언트가 쿠키로 보낸 세션ID와 대조해서 확인하지만,
토큰을 사용하면 요청을 받은 서버는 토큰이 유효한지만 확인한다.
토큰 인증이 세션에 비해 서버에 부하가 덜하다.
작동방식
- 사용자가 아이디와 비밀번호로 로그인을 한다.
- 서버 측에서 해당 정보를 검증한다.
- 정보가 정확하다면 서버 측에서 사용자에게 Signed 토큰을 발급한다.
- 클라이언트 측에서 전달받은 토큰을 저장해두고, 서버에 요청을 할때마다 해당 토큰을 서버에 함께 전달한다. 이때 HTTP 요청 헤더에 토큰을 포함시킨다.
- 서버는 토큰을 검증하고, 요청에 응답한다.
토큰 기반 인증
인증받은 사용자들에게 토큰을 발급하고, 서버에 요청을 할 때 헤더에 토큰을 함께 보내도록 하여 클라이언트 측에서 유효성을 검사를 한다.
즉, 서버에서 고객의 정보를 유지 하지 않기 때문에 이를 Stateless Server라고 부른다.
JWT
JWT는 일반적으로 클라이언트와 서버, 서비스와 서비스 사이 통신 시 권한 인가(Authorization)를 위해 사용하는 토큰이다. URL에대해 안전한 문자열로 구성되어 있기 때문에 HTTP 어디든(URL, Header, …) 위치할 수 있다.
JWT의 구조
JWT는 ”.” 을 기준으로 HEADER / PAYLOAD / SIGNATURE로 나뉜다.
HEADER.PAYLOAD.SIGNATURE
Header
JWT를 검증하는데 필요한 정보를 가진 JSON 객체는 Base64 URL-Safe 인코딩된 문자열이다.
헤더(Header)는 JWT를 어떻게 검증(Verify)하는가에 대한 내용을 담고 있다. 즉 alg는 3번째 값인 서명 값을 어떤 알고리즘으로 만들지 적혀 있다.
{
"alg": "ES256",
"kid": "Key ID"
}Payload
JWT의 내용이다. 페이로드(Payload)에 있는 속성들을 클레임 셋(Claim Set)이라 부른다.
클레임 셋은 JWT에 대한 내용(토큰 생성자(클라이언트)의 정보, 생성 일시 등)이나 클라이언트와 서버 간 주고 받기로 한 값들로 구성된다.
{
"iss": "jinho.shin",
"iat": "1586364327"
}Signature
누군가 JWT를 탈취하여 수정한 후 서버로 보낼 수 있습니다. 이 경우에 대비해 다른 사람이 위변조 했는지 검증하기 위한 부분이다.
서명은 헤더의 인코딩 값, 정보의 인코딩 값을 합친 후 비밀키로 해쉬를 하여 생성한다.
서명은 헤더의 alg에 정의된 알고리즘과 비밀 키를 이용해 성성하고 Base64 URL-Safe로 인코딩한다.
완성된 JWT는 헤더의 alg, kid 속성과 공개 키를 이용해 검증할 수 있다. 서명 검증이 성공하면 JWT의 모든 내용을 신뢰할 수 있게되고, 페이로드의 값으로 접근 제어나 원하는 처리를 할 수 있게된다.
장점
인가를 위해 서버가 별도로 저장하는 경우가 없다. 이를 stateless 하다고 표현한다.
단점
데이터 증가에 따른 네트워크 부하 증가
모든 요청에 대해서 토큰이 전송되므로 토큰에 담기는 정보가 증가할 수록 네트워크 부하가 증가하다. 그래서 보통 약자가 많이 사용된다.
Self-contained
토큰 자체에 정보를 담고 있다. JWT가 만료시간 전에 탈취당하면 서버에서 할 수 있는 것이 없다.
즉, 서버가 토큰에 대한 통제력을 가지고 있지 않다.
Stateless
JWT는 상태를 저장하지 않기 때문에 한번 만들어지면 제어가 불가능하다. 토큰을 임의로 삭제하는 것이 불가능하므로 만료 시간을 꼭 넣어 주어야 한다.
보완점
최초 로그인을 하면,
- 만료시간이 짧은 Access 토큰
- 만료시간이 매우 긴 Refresh 토큰
을 모두 부여한다. 이후에, refresh에 대한 상응 값은 데이터베이스에 저장한다.
유저의 access 토큰이 기한을 다하면, refresh 토큰을 보내면 저장된 값과 비교하여 맞으면 Access 토큰을 재발급 해준다.
OAuth
OAuth란 특정 애플리케이션이 다른 애플리케이션의 정보에 접근할 수 있는 권한을 관리하는 프로토콜이다.
JWT가 과일이라면 OAuth는 과일을 담는 상자라고 볼 수 있다.
JWT는 Token의 한 형식이고, OAuth는 하나의 Framework이다.
여기서 OAuth가 Framework인 이유는
- 토큰을 요청할 때 사용할 수 있어야하는 요청 및 응답의 순서와 형식만 있다.
- 각기 다른 시나리오에서 어떤 방식으로 권한 부여 유형을 사용할지 정한다.
물론 Auth Framework를 통해 나온 OAuth Bearer token과 단순한 JWT 토큰은 차이가 있다.
OAuth Token은 어떤 사용자의 정보와 같은 중요한 정보가 있는 토큰이 아니다. 그래서 이 토큰을 사용하는 사용자는 이 토큰이 가지고 있는 정보에 대해서 아는 바가 전혀 없다.
OAuth Token이 가지고 있는 정보는 일련의 랜덤한 문자열인데, 이는 일종의 Pointer로 OAuth Framework로 들어가서 해당 정보가 저장되어 있는 주소를 확인할 수 있는 인식표이다.
물론 이때 토큰이 JWT 유형의 토큰이 될 수도 있다.
반대로 JWT 토큰은 명확한 정보를 가지고 있는 토큰이다.
토큰의 크기는 300 ~ 500 byte. 혹은 가지고 있는 속성 정보에 따라 더 커지기도 한다.
이 때문에 데이터베이스에서 사용자 정보를 조작하더라도 토큰에 직접 적용할 수 없는 문제점이 있고, 토큰이 커지면서 주고 받는 데이터 트래픽 크기에 영향을 미칠 수 있는 단점이 있다.
캐시
데이터나 값을 미리 복사해 임시로 저장해 두는 장소
사이트를 불러 올 때 전에 불러 왔던 사진을 접속 때 마다 불러오면 데이터의 낭비를 일으킨다.
캐시를 통해 클라이언트에 저장해둘 수 있으며 주기적으로 비워줘야한다.
URI, URL, URN에 대해서
URI (Uniform Resource Identifier)
인터넷 자원을 나타내는 고유 식별자이다. URI 에 I 가 Identifier이다. 인터넷에 있는 자료의 id 이다, 라고 생각하면 좋을 것 같다. 다른 자료가 똑같은 이름을 가지고 있으면 안되겠죠? 그래서 URI 는 유일해야한다.
URL (Uniformed Resource Locator)
프로토콜 포함
해당 자원의 위치, Path를 의미
일반적으로 사이트 도메인을 자주 의미함.
웹 상 뿐만 아니라 컴퓨터 네트워크상의 자원은 모두 나타낼 수 있다.
URN (Uniformed Resource Name)
프로토콜 포함 X
해당 자원의 이름을 의미
독립적인 자원 지시자
Page 이후 부분까지 포함
요약
- URI 는 네트워크 상 자원을 가리키는 일종의 고유 식별자(ID) 이다.
- URL, URN 은 URI 에 포함되는 개념이며 URL 은 자원의 위치, URN 은 자원의 이름 을 의미한다.
REST, REST API, RESTful 이란?
REST는 Representational State Transfer의 약자이다. 간단히 말해서 URI와 HTTP 메소드를 이용해 객체화된 서비스에 접근하는 것이다. REST의 요소로는 크게 리소스, 메소드, 메세지 3가지 요소로 구성된다. 예를 들어 “이름이 Tom인 사용자를 생성한다.” 라는 호출이 있을 때 “사용자”는 생성되는 리소스, “생성한다.”라는 행위는 메소드, 그리고 “이름이 Tom인 사용자”는 메세지가 된다. 즉 리소스는 http://myweb/users라는 형태의 URI로 표현되며, 메소드는 HTTP Post, 메세지는 JSON 문서를 이용해서 표현된다. HTTP에는 여러가지 메소드가 있지만 REST에서는 CRUD에 해당하는 4가지의 메소드 GET, POST, PUT, DELETE를 사용한다. REST는 리소스 지향 아키텍쳐 스타일이라는 정의에 맞게 모든 것을 명사로 표현하며 각 세부 리소스에는 id를 붙인다.
Restful하게 API를 디자인한다는 것은 URI를 규칙에 맞게 잘 설계했는지의 여부이다. 규칙의 항목으로는 아래와 같다.
- 동일한 URI(End point)의 행위에 맞게 POST, GET, DELETE, PATCH등의 메소드를 사용한다.
- 명사를 사용한다. 리스트를 표현할 때는 복수형을 사용한다.
- URI Path에 불필요한 파라미터를 넣지 않는다. 즉, 단계를 심플하게 설계한다.
REST API 장점, 단점
stateless의 장점:
stateless를 통해 API를 수백만 명의 동시 사용자로 확장할 수 있다. 세션과 관련된 의존 항목이 없기 때문에 모든 서버에 배치할 수 있다
서버는 각 클라이언트가 어플리케이션에서 “위치”를 알고 있다. 필요한 모든 정보가 요청마다 발송되기 때문이다.
stateless를 통해 REST API는 서버 측 동기화와 관련된 모든 복잡성을 제거한다.
stateless의 단점:
고객이 요청할 때마다 추가 정보를 보내야 함
데이터 중복 전송은 네트워크 성능을 저하시킬 수 있음
stateless는 서버측의 응용 프로그램 행위 제어도 감소
HTTP 1,2,3의 차이
HTTP 1.1
비연결지향(connectionless)
클라이언트가 서버에 리소스 요청한 후 응답 받으면 연결을 끊어버리는 특징이다.
서버에 부담을 주지 않도록 클라이언트 요청을 처리하면 연결을 끊어 서버의 부담을 줄인다. 하지만 리소스를 요청할 때마다 새롭게 연결해야 되므로 오버헤드 비용이 발생한다. (RTT 증가, 네트워크 성능 저하)
오버 헤드 해결 방법:
요청 헤더 connection:keep-alive 속성으로 지속적 연결 상태(persistent connection)을 유지한다.
요청을 할 때마다 연결하지 않고 기존의 연결을 재사용하는 방식으로 HTTP/1.1부터는 지속적 연결 상태가 기본이고 해제하기 위해서는 명시적으로 요청 헤더를 수정해야 한다.
파이프라이닝: http/1.1의 connection 당 하나의 요청 처리를 개선하는 방법 중 파이프라이닝이 존재한다. connection을 통해 다수개의 파일을 요청/응답 받는 기법
무상태성 (stateless)
각각의 요청은 독립적이라고 여겨지는 특성으로 서버는 클라이언트의 상태를 유지하지 않는다.
요청이 처리되면 연결이 끊어지기 때문에 클라이언트의 이전 상태를 알 수 없다. connectless로부터 파생되는 특징이다.
클라이언트가 과거에 로그인을 해도 로그 정보를 유지할 수 없다. 웹 서비스를 하기위해서 쿠키나 세션 또는 토큰 방식의 OAuth 및 JWT가 사용된다.
동시 전송이 불가능하고 요청과 응답이 순차적으로 이루어진다. HTTP문서 안 다수의 리소스를 처리하려면 Latency(대기시간)이 길어진다.
HTTP/1.1 단점
HOL (Head of Line) blocking: 특정 응답의 지연
http/1.1의 connection 당 하나의 요청 처리를 개선하는 방법 중 파이프라이닝이 존재
connection을 통해 다수개의 파일을 요청/응답 받는 기법
RTT (round trip time) 증가
하나의 connection에 하나의 요청을 처리하면서 매 요청별로 connection이 연결되기 때문에 TCP 상에서 동작하는 HTTP 특성상 3- way handshake가 반복적으로 일어나 불필요한 RTT 증가와 네트워크 지연을 일으켜 성능을 저하시킨다
무거운 header 구조 (ex. 쿠키)
헤더에 많은 메타 정보를 저장한다
매 요청시마다 중복된 header값을 전송하게 되며 해당 domain에 설정된 cookie 정보도 매 요청시 마다 헤더에 포함되어 전송된다
전송하는 값보다 헤더 값이 더 큰 경우도 있다.
HTTP 3.0 과 HTTP 2.0 비교
| 구분 | HTTP 2.0 | HTTP 3.0 |
|---|---|---|
| 헤더압축 | 가능 | 가능 |
| 스트림 전송 | 가능 | 가능 |
| 멀티플렉싱 | 가능 | 가능 |
| 기반프로토콜 | TCP | UDP |
| 속도 | 상대적으로 느림 | 상대적으로 빠름 |
| 암호화 | 지원 | 지원 |
| CPU 부하 | 감소 | 증가 |
HTTP
HyperText Transfer Protocol 또는 HyperTexT Protocol의 약자.
최초 개발시 HTTP의 의미는 하이퍼텍스트를 빠르게 교환하기 위한 프로토콜의 일종으로 즉, HTTP는 서버와 클라이언트의 사이에서 어떻게 메시지를 교환할지를 정해놓은 규칙을 지칭한다.
HTTP 응답코드
HTTP 통신을 기반으로 하고있는데, 통신을 할 때, 그 결과를 알려주기위해서 HTTP 상태코드라는 것을 사용합니다. 클라이언트가 보낸 요청의 처리 상태를 알려주는 기능을 함.
1xx - 요청이 수신되어 처리중
잘 사용하지않는다.
2xx - 정상 처리됨
200 - ok(정상적으로 잘 처리해서 반환 한 경우)
201 - created(post등으로 서버에서 자원을 생성한 경우)
202 - accepted(요청이 접수되었으나 처리가 안된 경우 - 배치 처리 같은 곳에서 사용한다.)
204 - no content(성공적으로 수행했는데, 응답 페이로드 본문에 보낼게 없는 경우)
3xx - 요청을 완료하려면 추가 행동이 필요
웹 브라우저는 3xx 응답 결과에 Location header가 있으면 그 위치로 자동으로 이동한다.
영구 리다이렉션 - 특정 리소스의 URI가 영구적으로 이동(301,308), 원래의 URL을 사 용하지않아서 검색 엔즌 등에서도 변경을 인지한다.
일시 리다이렉션 - 일시적인 변경(302,307,303), URI가 일시적으로 변경. 따라서 검색 엔진 등에서 URL을 변경하면 안된다. 302를 가장 많이 쓰는데, 303과 307을 권장함
특수 리다이렉션 - 결과 대신 캐시를 사용(300,304),
PRG (Post/Redirect/Get) - Post했을 때, 이미 있으면 302 로 Location 주면서 일시적으로 리다이렉션하게해서 중복 주문과 같은 오류를 방지할 수 있다.
300 - multiple choices(거의 안씀)
301 - Moved Permanently
리다이렉트시 요청 메서드가 GET으로 변하고, 본문이 제거될 수 있음.
308 - Permanent Redirect
301과 기능은 같지만 리다이텍트시 요청 메서드와 본문을 유지한다.
302 - Found
리다이렉트시 요청 메서드가 GET으로 변하고, 본문이 제거될 수 있다. 301이랑 똑같다.
303 - See Other
리다이렉트시 요청 메서드가 GET으로 변경된다.
307 - Temporary Redirect
302와 기능이 같음. 리다이렉트시 요청 메서드와 본문이 유지된다. 요청 메서드 변경은 절대 불가능
304 - Not Modified
캐시를 목적으로 사용. 클라이언트에게 리소스가 수정되지않았음을 알려줌. 캐시에 있는게 써도되는건지 물어본거에 써도 된다고 알려줌. 바디메세지를 포함하면 안된다.(로컬캐시를 사용해야하기 때문이다)
4xx - 클라이언트 오류가 나서 서버가 요청을 처리할 수 없음.(잘못된 문법 등등)
오류의 원인이 클라이언트에 있는 경우를 의미
400 - Bad Request
요청이 잘못된 것(요청 구문이나 API 스펙이 안맞은 경우) 백엔드에서 철저하게 다 막아줘야한다.
401 - Unauthorized
인증이 안된 경우. WWW-Authenticate 헤더와 함꼐 인증 방법을 설명
인증(누구인지 확인) 인가(권한부여, ADMIN 권한처럼 특정 리소스에 접근할 수 있는 권한)
403 - Forbidden
요청은 이해했으나, 승인은 거부한 경우. 인증은 됐지만, 인가가 안된 경우
404 - Not Found
요청 리소스가 서버에 없음. 또는 클라이언트가 권한이 부족한 리소스에 접근할 때 해당 리소스를 숨기고 싶을 때.
405 Method Not Allowed
요청한 메소드는 서버에서 알고 있지만, 제거되었고 사용할 수 없습니다. 예를 들어, 어떤 API에서 리소스를 삭제하는 것을 금지할 수 있습니다. 필수적인 메소드인 GET과 HEAD는 제거될 수 없으며 이 에러 코드를 리턴할 수 없습니다.
5xx - 서버 문제, 서버가 정상 요청을 처리하지 못하는 경우.
서버 문제(디비 접근이 불가능하거나 NullPointerException이 터지는 경우 등등)
503 - Service Unavailable
섭다하고 작업할 때 보여주는거. Retry-After헤더로 공지사항도 띄워줄 수 있음.
서버에서 문제가 터졌을 때, 500대 에러를 만들어야함. 데이터 숨기거나 할거는 다 400대로 던져야한다.
즉, 비즈니스 로직 상의 예외케이스는 500대를 던지면 안된다.
500대를 내는거는 쿼리에 문제가 있거나 디비에 문제가 있거나 널포인트가 뜬다거나하는 상황에서 사용한다.
HTTPS
HTTP
HTTP는 Hypertext Transfer Protocol의 약자로 서로 다른 시스템들 사이에서 통신을 주고받게 해주는 가장 기초적인 통신 규약을 의미한다.
HTTP는 기본적으로 평문 데이터 전송을 원칙으로 하기 때문에 개인의 프라이버시가 오가는 서비스들(전자상거래, 전자메일, 사내문서)에 사용하기 힘들다.
HTTPS
HTTP와 반대로 HTTPS는 Hypertext Transfer Protocol over Secure Socket Layer의 약자로 HTTP에 보안 기능이 추가가 된 형태라고 보면 된다.
넷스케이프 커뮤니케이션즈 코퍼레이션이 개발했으며, 전자 상거래에서 널리 쓰인다.
HTTP는 서버에서 브러우저로 전송되는 정보가 암호화되지 않기 때문에 데이터가 해커에 의해 쉽게 도난당할 수 있다는 것이 특징이다. 하지만 HTTPS는 SSL(보안 소켓 계층)을 사용함으로써 이 문제를 해결했다. SSL은 서버와 브라우저 사이에 안전하게 암호화된 연결이 일어나도록 도와주어 민감한 정보가 도난당하지 않게 이를 방지해주는 역할을 한다.
HTTPS의 원리
공개 키 방식(Public Key Infrastructure)은 두 개의 키를 갖게 되며, A키로 암호화 하면 B키로 복호화가 가능하며, 반대로 B키로 암호화를 하면 A키로 복호화를 할 수 있다. 여기서 두 개의 키 중 하나는 공개 키(public key)이고 다른 하나는 비공개 키(private key)가 된다. 비공개 키는 private한 사용자가 가지고 있게 되며, 공개 키는 타인에게 공개되는 키이다. 유저가 공개 키를 이용하여 데이터를 암호화한 뒤, 비공개 키의 소유자에게 전달하면, 비공개 키의 소유자는 비공개 키로 복호화 하여 그 데이터를 얻는 간단한 원리이다.
SSL
SSL은 전자상거래에서의 데이터 보안을 위해서 개발한 통신 레이어다. SSL은 표현 계층의 프로토콜로 응용 계층 아래에 있기 때문에, 어떠한 응용 계층의 데이터라도 암호화해서 보낼 수 있다.
SSL 동작방식
- SSL 인증서를 발급받고자 하는 A업체는 인증된 CA(Certificate Authority)기관에 A의 공개키와 사이트 정보를 전달한다.
- CA는 검증을 거친 후에 CA 개인키로 ‘A 공개키와 사이트 정보’를 암호하여 인증서를 생성한다. 이 인증서는 A업체로 전달된다.
- 인증된 CA기관의 공개키는 웹브라우저에 저장되어 있다. A사이트에 접속하고자 하는 PC B는 A사이트에 요청을 한다.
- 요청(Agent Hello)하는 과정에서 A는 B에게 ‘랜덤한데이터 + 사용가능 암호화방식 + 세션 아이디’를 전달한다. 이에 대한 응답(Server Ack)에서 B는 ‘랜덤한 데이터 + 사용가능 암호화방식 + 인증서)를 전달한다.
- handshake간에 주고 받은 랜덤한 데이터를 조합하여 pre master secret이라는 키를 생성한다(pre master secret는 대칭키로 실제 데이터 통신에 쓰일 키이다).
- B는 브라우저에 내재되어 있는 CA 공개키로 인증서를 복호화한다(CA의 개인키로 암호화 - 공개키로 복호화 : 공개키 방식). 이 과정에서 B는 A의 공개키와 사이트 정보를 얻을 수 있다.
- 위 단계에서 인증서가 믿을 수 있고 인증된 것임을 확인할 수 있다(CA 공개키로 복호화가 됐기 때문).
- 사용자B에게는 현재 대칭키로 쓰일 pre master key와 A의 공개키가 있다. pre master key를 A공개키로 암호화하여 A사이트로 전송한다.
- A는 자신의 개인키로 보내온 패킷을 복호화하여 pre master key를 얻는다.
- pre master key는 일련의 과정을 거쳐서 master key > session key를 생성하고, 이는 통신을 위한 대칭키로 사용된다.
간략
- handshake 과정의 랜덤한 데이터로 pre master secret 생성
- 인증서 복호화(CA 공개키 - 브라우저 내저)로 사이트 공개키 획득
- 사이트 공개키로 pre master secret 암호화 후, 사이트 전달
- 사이트 개인키로 복호화 후, pre master secret 획득
- 일련의 과정을 거쳐서 master secret > session key 생성
- session 키로 대칭키 방식으로 정보 송수신
SSL Stripping이란?
SSL Strip은, SSL 통신을 하고있는 네트워크 상에서 SSL 암호 프로토콜을 사용하지 못 하게 평문으로 전송되는 HTTP 프로토콜로 바꾸어 전송하는 공격기법 이다.
이를 방지하기 위한 방법으로는,
게이트웨이이의 MAC address를 정적으로 세팅하는 것이 있다.
GET과 POST의 차이
POST
POST라는 영어 단어는 부치다, 제출하다라는 뜻을 가지고 있다. 예를 들어 우리가 어디에 서류를 제출하는 것은 우리에 대한 정보를 제출하여 추가하기 위함이다. 이러한 상황과 유사하게 POST 방식은 데이터를 서버로 제출하여 추가 또는 수정하기 위해서 데이터를 전송하는 방식이다.
POST의 특징
URL에 데이터를 노출하지 않고 요청한다.
데이터를 Body에 포함시킨다.
URL에 데이터가 노출되지 않아서 기본 보안은 되어있다.
전송하는 길이에 제한이 없다.
GET
영어 GET은 가져오다라는 뜻을 가진 단어이다. 우리가 필요한 정보를 얻기 위해 도서관에서 책을 빌려 가져오는(GET)상황과 유사하게 GET은 어떠한 정보를 가져와서 조회하기 위해서 사용되는 방식이다.
GET의 특징
URL에 데이터를 포함시켜 요청한다.
데이터를 헤더에 포함하여 전송한다.
URL에 데이터가 노출되어 보안에 취약하다.
전송하는 길이에 제한이 있다.
정리
GET 방식은 주소 뒤에 쿼리스트링이 그대로 전달되어 보안성이 떨어지고 전송속도는 빠름
→ Get은 주로 웹 브라우저가 웹 서버에 데이터를 요청할 때 사용
POST 방식은 주소가 전달 될 때 인코딩하여 전달되어 보안성이 높지만 전송속도가 느리다
→ Post는 웹 브라우저가 웹 서버에 데이터를 전달하기 위해 사용
HTTP 멱등성
멱등성이란, 수학에서 사용하는 용어에서 유래한 것으로. 연산을 여러 번 적용하더라도 결과가 달라지지 않는 성질을 뜻한다.
이 멱등성을 HTTP Method에 적용하면 다음과 같은 의미를 가진다. 동일한 요청을 한번 보내는 것과 여러번 연속으로 보내는 것이 같은 효과를 가지고, 서버의 상태도 동일하게 남을 때 해당 HTTP Method가 멱등성을 가진다고 한다.
HTTP Method의 멱등성에서 알아두어야 할 점이 있다. 결과가 의미하는 것이 응답 상태코드가 아닌 서버의 상태라는 것이다. 예를 들어, 똑같은 요청을 했을 때 응답하는 상태코드가 바뀌더라도 서버의 상태가 항상 같은 상태라면 멱등성이 있다고 판단한다.
우리가 흔히 사용하는 HTTP Method는 GET, POST, PUT, PATCH, DELETE가 있다. HTTP 스펙에 명시된 것에 의하면, GET, PUT, DELETE는 멱등성을 가지도록, POST와 PATCH는 멱등성을 가지지 않도록 구현해야 한다.
CORS란?
CORS란 Cross-Origin Resource Sharing의 약자로, 출처가 다른 리소스도 공유할 수 있도록 하는 정책을 말한다. 보안상의 이유로 원칙적으로는 오직 출처가 동일한 리소스만 공유할 수 있다. (Same-Origin Policy)
클라이언트가 요청메세지의 Origin헤더 해당 출처를 적어보내고, 그 응답으로 서버로부터 받은 응답메세지의 Access-Control-Allow-Origin의 내용을 자신이 보냈던 Origin헤더 내용을 비교해본 후 유효한 응답인지 아닌지를 결정하는 메커니즘으로 동작한다.
CORS 해결방법
- Access-Control-Allow-Origin 응답 헤더 세팅
서버측 응답에서 접근 권한을 주는 헤더를 추가하여 해결 - cors 모듈 사용
아무 옵션없이 설정하면 모든 cross-origin 요청에 대해 응답이므로, 특정 도메인이나 특정 요청에만 응답하게 옵션을 설정하는 것이 좋다. - 특정 도메인 접근 허용
- 특정 요청 접근 허용
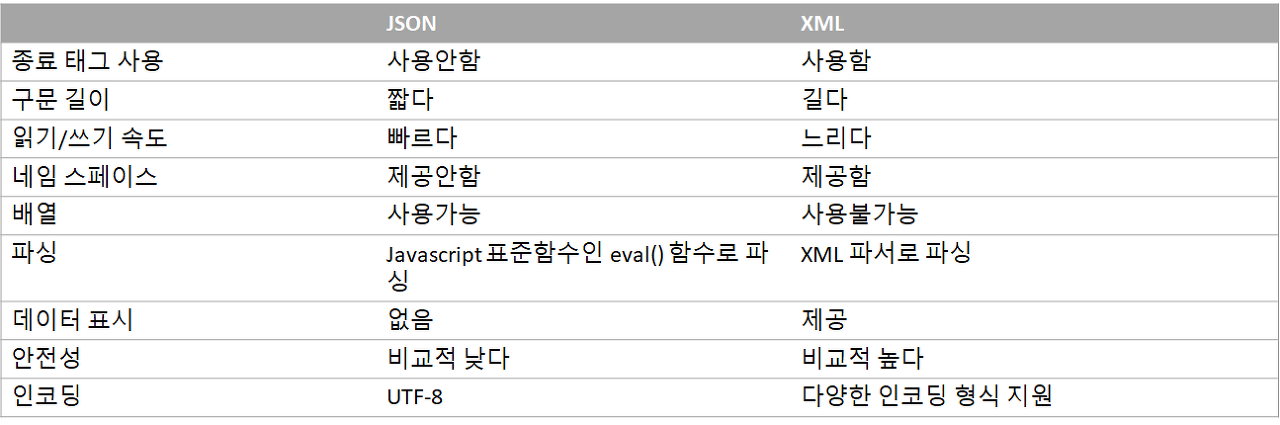
JSON, XML의 차이
XML(eXtensible Markup Language)
HTML과 매우 비슷한 문자 기반의 마크업 언어이다.
사람과 기계가 동시에 읽기 편한 구조로되어있다.
HTML처럼 데이터를 보여주는 목적이 아닌 데이터를 저장하고 전달하는 목적으로 만들어졌다.
XML 태그는 HTML 태그 처럼 미리 정의 되어 있지 않고, 사용자가 직접 정의할 수 있다.
JSON(JavaScript Object Notation)
브라우저 통신을 위한 속성-값 또는 키-값 쌍으로 이루어진 데이터 포맷
JSON과 XML 공통점
데이터를 저장하고 전달하기 위해 고안되었다.
기계 뿐아니라 사람도 쉽게 읽을 수 있다.
계층적인 데이터 구조를 가진다.
다양한 프로그래밍 언어에 의해 파싱될 수 있다.
XMLHttpRequest 객체를 이용하여 서버로부터 데이터를 전송받을 수 있다.
JSON과 XML의 차이점
MIME이란?
MIME이란?
Multipurpose Internet Mail Extensions의 약자로 간략히 말씀을 드리면 파일 변환을 뜻한다고할 수 있다.
MIME는 이메일과 함께 동봉할 파일을 텍스트 문자로 전환해서 이메일 시스템을 통해 전달하기 위해 개발되었기 때문에 이름에 Internet Mail Extension이다. 그렇지만 현재는 웹을 통해서 여러형태의 파일 전달하는데 쓰이고 있다.
AWS란?
아마존닷컴에서 개발한 클라우드 컴퓨팅 플랫폼이다.
Amazon Web Services는 아마존(Amazon)에서 제공하는 클라우드 서비스로, 네트워킹을 기반으로 가상 컴퓨터와 스토리지, 네트워크 인프라 등 다양한 서비스를 제공하고 있다.
비즈니스와 개발자가 웹 서비스를 사용하여 확장 가능하고 정교한 애플리케이션 구축하도록 지원하여 준다.
현재 소규모 법인(회사) 및 개인 을 포함한 다양한 사용자들이 사용하고 있으며, 클라우드 컴퓨팅의 장점을 이용하기 위해 많은 거대 기업에서도 활용하고 있다.
디자인 패턴
소프트웨어를 설계할 때 특정 맥락에서 자주 발생하는 고질적인 문제들이 또 발생했을 때 재사용할 할 수있는 훌륭한 해결책
“바퀴를 다시 발명하지 마라(Don’t reinvent the wheel)”
이미 만들어져서 잘 되는 것을 처음부터 다시 만들 필요가 없다는 의미이다.
프로그램을 설계할 때 발생했던 문제점들을 객체 간의 상호 관계 등을 이용하여 해결할 수 있도록 하나의 ‘규약’ 형태로 만들어 놓은 것
싱글톤 패턴
싱글톤 패턴(Singleton Pattern)의 의미를 보자면 하나의 클래스에 오직 하나의 인스턴스만 가지는 패턴이다. 즉, 생성자의 호출이 반복적으로 이뤄져도 실제로 생성되는 객체는 최초 생성된 객체를 반환 해주는 것이다. 쉽게 얘기하면 단 한 개의 물건으로 여러 사함이 함께 공유하며 사용하는 방법이다.
Factory Method Pattern
슈퍼클래스에서 객체를 생성하기 위한 인터페이스를 제공하지만 서브클래스가 생성될 객체의 유형을 변경할 수 있도록 하는 생성 디자인 패턴이다. 즉, 객체를 만드는 부분을 Subclass에 맡기는 패턴이다.
탬플릿 메소드 패턴
상속을 통해 슈퍼클래스의 기능을 확장할 때 사용하는 가장 대표적인 방법.
변하지 않는 기능은 슈퍼클래스에 만들어두고 자주 변경되며 확장할 기능은 서브클래스에서 만들도록 한다.
하위 클래스에서 사용되지만, 변하지 않는 기능을 상위 클래스에 저장해 놓고 확장할 기능은 서브 클래스에서 만들도록 설계한다는 내용을 담고 있다.
어댑터 패턴
어댑터 패턴은 서로 다른 인터페이스를 가진 두 클래스를 어댑터 클래스로 인터페이스를 통일 시켜 사용하는 방법이다.
Observer Pattern
옵저버 패턴은, 한 객체의 상태가 바뀌면 그 객체에 의존하는 다른 객체들에게 연락이 가고, 자동으로 정보가 갱신되는 1:N 관계(혹은 1대1)를 정의한다.
인터페이스를 통해 연결하여 느슨한 결합성을 유지하며, Publisher와 Observer 인터페이스를 적용한다.
Strategy Pattern
전략 패턴(strategy pattern)은 정책 패턴(policy pattern)이라고도 하며, 객체의 행위를 바꾸고 싶은 경우 ‘직접’ 수정하지 않고 전략이라고 부르는 ‘캡슐화한 알고리즘’을 컨텍스트 안에서 바꿔주면서 상호 교체가 가능하게 만드는 패턴이다.
State Pattern
행동 패턴으로, 상태변화에 따라 클래스의 행동을 바꾸는 패턴이다.
상태 패턴에서는 다양한 상태를 나타내는 객체와 상태 객체가 변경됨에 따라 동작이 달라지는 컨텍스트 객체를 생성한다.
State Pattern 상태 패턴 사용이 적합한 경우
현재 상태에 따라 행동(기능)이 변화되는 객체인 경우, 상태의 가짓수가 많고, 상태가 빈번하게 변경되는 경우
클래스의 상태 필드에 따라서 기능을 변경하는, 수많은 조건문으로 코드가 복잡해진 경우
상태 필드를 변경하는 조건 코드가 많이 중복해서 사용되고 있는 경우
장점
상태를 관리하는 로직을 클래스 객체에서 분리해 관리할 수 있습니다. (단일책임원칙)
기존 상태 클래스와 컨텍스트 객체의 수정 없이 새로운 상태를 추가할 수 있습니다. (개방/폐쇄원칙)
상태를 관리하기 위한 조건 코드를 간단하게 만들 수 있습니다.
단점
상태의 가짓수가 적고, 상태 변경도 드물다면, 상태 패턴을 적용하는 것은 과도할 수 있습니다.
클라우드 컴퓨팅이란?
언제든지 인터넷만 연결이 되어 있다면 연결 가능한 서버나 네트워크
클라우드 네이티브 - 클라우드의 이점을 최대로 활용해서 애플리케이션을 구축하고 실행하는 방식
SaaS (Software As A Service) 클라우드 서비스란?
SaaS 클라우드 서비스는 사용자가 소프트웨어를 온라인 서비스로 이용할 수 있도록 클라우드 플랫폼에 배치되어 구동되는 모델을 의미한다.
스케일 아웃(Scale-out)과 스케일 업(Scale-up)의 차이는?
서버확장을 위한 기술이다.
스케일 아웃 : 서버를 여러 대 추가하여 시스템을 확장하는 방법
스케일 업 : 서버에 CPU나 RAM 등을 추가하여 고성능의 부품, 서버로 교환하는 방법
MSA(Micro Soft Architecture)의 개념을 설명해라.
Microservice : 애플리케이션을 구성하는 서비스들을 독립적인 단위로 분해하여 구축하고 각 구성 요소들을 네트워크로 통신하는 아키텍쳐로 서비스 안정성과 확장성(Scaling)을 지원한다.
MSA : 단일 프로그램을 각 컴포넌트 별로 나누어 작은 서비스의 조합으로 구축하는 방법이다. 각 컴포넌트는 서비스 형태로 구현되고 API를 이용하여 타 서비스와 통신하게 된다.
MSA 장점과 단점
MSA의 장점
각각의 서비스는 모듈화가 되어 있고 모듈끼리 RPC 또는 message-driven API등을 이용하여 통신한다. 이러한 MSA는 각각 개별의 서비스 개발을 빠르게 하며, 유지보수도 쉽게 가능하다.
팀 단위로 기술 스택을 다르게 가져갈 수 있다. 회사가 java의 spring 기반이여도 MSA를 적용해 node.js로 블록체인 개발 모듈을 연동함에 무리가 없다.
서비스 별로 독립적 배포가 가능하다. 지속적인 배포(CD)의 쉬워짐
각각 서비스 부하에 따라 개별적으로 Scale-out이 가능하다.
MSA의 단점
모놀리식에 비해 상대적으로 많이 복잡하다. 서비스가 모두 분산되어 있어서 내부 시스템의 통신을 어떻게 가져갈지 정해야하고, 통신 장애나 서버 부하 등이 발생할 경우 트랜잭션 유지 방법을 결정하고 구현해야한다.
모놀리식에서는 단일 트랜잭션을 유지하면 되지만 MSA에서는 DB마다 서비스가 달라 트랜잭션 유지가 어렵다.
통합 테스트가 어렵다. 개발 환경과 실제 운영환경을 동일하게 가져가는 것이 쉽지 않다.
배포 시 다른 서비스들과 연동을 고려해야 한다.
도커란?
컨테이너 기반의 오픈소스 가상화 플랫폼
컨테이너 : 호스트OS 를 공유하며, 여러개의 컨테이너들이 서로 영향을 미치지 않고 독립적으로 실행되어 가볍다.
컨테이너의 생성은 ‘도커파일’을 사용한다. 가상화 할 프로그램들을 ‘도커파일’이란 DSL(Domain Specific Language) 형태로 작성한다.
생성과정
도커파일 > build = 도커이미지 생성
도커이미지 > run = 도커컨테이너 생성
도커 파일은 소스와 함께 버전관리도 된다.
도커 파일로 생성한 이미지들은 용량이 매우 커서 ‘도커허브’라는 곳에서 무료로 관리가 가능해 공개 이미지들을 다운로드 받을 수 있다.
컨테이너란?
호스트OS 를 공유하며, 여러개의 컨테이너들이 서로 영향을 미치지 않고 독립적으로 실행되어 가볍다.
컨테이너의 생성은 ‘도커파일’을 사용한다. 가상화 할 프로그램들을 ‘도커파일’이란 DSL(Domain Specific Language) 형태로 작성한다.
Docker(도커)와 Kubernates(쿠버네티스)
Docker는 컨테이너 기반의 가상화 기술이다. 기존에는 OS를 가상화하였기 때문에 Host OS 위에 Guest OS를 설치해야 했습니다. 하지만, 이러한 방식은 상당히 무겁고 느려 한계가 많이 있었다.
그래서 이를 극복하고자 프로세스를 격리시킨 컨테이너를 통해 가상화를 하는 Docker(도커)와 같은 기술들이 등장하게 되었고, 도커를 통해 구동되는 컨테이너를 관리하기 위한 Kubernates(쿠버네티스)가 등장하게 되었다.
쿠버네티스 클러스터의 기본 아키텍처에 대해 설명하라.
쿠버네티스 : 컨테이너화된 워크로드와 서비스를 관리하기 위한 이식할 수 있고, 확장 가능한 오픈소스 플랫폼
(컨테이너 관리 자동화와 배포/확장까지 해준다.)
클러스터 : 여러 대의 컴퓨터들이 연결되어 하나의 시스템 처럼 동작하는 컴퓨터들의 집합을 말한다. / 데이터 집단
클러스터링 : 각기 다른 서버를 묶어서 하나의 시스템처럼 동작하게 하며, 클라이언트에게 고가용성 서비스를 제공한다.
Active — Active 구조
서버들이 항상 Active(활동)상태 즉, 작업을 수행하고 있는 상태이다. 동일한 스토리지를 공유하며 L4에 의해 Load Balancing이 이루어진다.또한, L4에 의해 즉각적인 Fail Over가 이루어진다.
Active — Standby 구조
서버들의 상태가 Active(활동)상태와 Standby(대기)상태로 이루어져 있고, Standby서버는 Active서버가 장애발생시, 바로 Active상태로 바뀔 수 있도록 한다. 한마디로, Standby 서버는 예비서버이다.
Active서버 → Standby
서버 : Fail OverStandby(전 Active) → Active(전 Standby) : Fail Back
클러스터 분석 : 주어진 데이터들의 특성을 고려해 데이터 집단(클러스터)을 정의하고 데이터 집단의 대표할 수 있는 대표점을 찾는 것으로 데이터 마이닝의 한 방법이다.
쿠버네티스 아키텍처 : run을 하면 실행되고 stop을 하면 멈춘다.
중앙(Master)에서 API 서버와 상태 저장소를 두고 서버(Node)의 에이전트(kubelet)와 통신하는 단순 구조.
하지만, 앞에서 얘기한 개념을 여러 모듈로 쪼개어 구현하고 다양한 오픈소스를 사용하기 때문에 설치가 까다롭고 언뜻 구성이 복잡해 보인다.
모니터링 툴 이란?
클라우드 모니터링은 클라우드 기반 IT 인프라의 상태를 평가하는 프로세스이다. 클라우드 모니터링 도구를 사용하는 조직은 클라우드 환경의 가용성/성능/보안을 사전에 모니터링하여 문제가 최종 사용자 환경에 영향을 주기 전에 찾아서 해결할 수 있다.
쿠버네티스에서 Auto Scaling 원리에 대해 설명하라.
CPU, memory 사용량에 따른 확장은 기본이고 현재 접속자 수와 같은 값을 사용할 수도 있다. 컨테이너의 개수를 조정하는 Horizontal Pod Autoscaler(HPA), 컨테이너의 리소스 할당량을 조정하는 Vertical Pod Autoscaler(VPA), 서버 개수를 조정하는 Cluster Autosclaer(CA) 방식이 있다.
CI/CD
지속적인 통합(Continous Intergration)은 개발자가 작업한 코드를 자동으로 테스트 하고 테스트에 통과하면 통합하여 저장한다.
지속적인 배포(Continous Deployment)은 작업한 코드 및 변경사항들을 테스트를 거쳐 리포지토리로 업로드 되고 실 서비스 배포로 릴리즈까지 자동화 하는 것을 말한다.
고가용성이란?
고가용성(HA, High Availability)이란 서버와 네트워크, 프로그램 등의 정보 시스템이 상당히 오랜 기간 동안 지속적으로 정상 운영이 가능한 성질을 말한다.
DevOps < Dev(개발) Ops(운영) >
애플리케이션 개발-운영 간의 협업 프로세스를 자동화하는 것을 말하며, 결과적으로 애플리케이션의 개발과 개선속도를 빠르게 한다.
DevOps는 ‘개발과 IT’운영간의 프로세스를 통합하여 궁극적으로는 ‘고객에게 뛰어난 품질의 서비스를 빠르게 제공한다.’ 는 개발 방법론이다.
과거 새로운 서비스를 출시하기 위해서 오랜기간 작업 후 배포했던 것과 달리, 현재는 서비스 출시 속도가 다르고 업데이트 주기 또한 빈번해 졌습니다. 그렇기 때문에 개발된 소프트웨어가 시스템의 안정성을 유지하면서 사용자에게 빠르게 제공될 수 있도록[개발 - 테스트 - 배포 - 운영]의 업무 사이클을 자동화된 단일 워크 플로우로 통합할 필요성이 생기게 된 이유이다.
소스 코드 제어(SCM: Source Code Management)
서비스는 주로 팀 단위로 개발이 되는데, 서로 다른 팀에서 개발한 코드에 대한 버전과 이력을 관리해야 한다.
CI/CD
지속적인 통합과 배포를 통해 애플리케이션 개발 단계를 자동화 하여 고객에게 보다 짧은 주기로 서비스를 제공하고 개선하는 방법이다.
모니터링
업데이트 빈도가 늘어남에 따라 일반적으로 요구되는 엄격한 테스트를 매번 수행할 필요가 없다. 따라서, 데브옵스 환경에서는 실시간으로 앱 성능 모니터링을 통하여 오류, 개선사항을 찾아 해결하는 것이 중요하다.
서버리스란?
서버리스 컴퓨팅이란 IT 인프라를 데이터센터 또는 클라우드에 준비 없이 필요한 기능을 함수로 구현해서 관리하는 것을 의미한다.
그리고,
서버리스 컴퓨팅은 IT 인프라를 데이터센터 또는 클라우드에 준비 없이, 필요한 기능을 함수(Function) 형태로 구현하고, 자동 스케일링 방식으로 시시각각 변하는 자원 수요를 지원하며 전통적인 백엔드를 대신한다. 따라서 서버리스 컴퓨팅을 FaaS(Function as a Service) 라고도 하고 백엔드 시스템을 보이지 않는 서비스로 추상화하였기 때문에 BaaS(Backend as a Service) 라고도 한다.