Info
home server 구축 과정을 정리한 페이지 입니다.
계획
미니pc 를 통해서 ProxmoxVE 를 OS 로 설치한 뒤 Opnsense kubernetes 등 여러가지 도구들을 사용하여 실제 여러 홈페이지 및 application 을 운영해 볼 생각이다.
미니pc 스펙
모델명 : FIREBAT T8 플러스 N100 CPU : N100 (4core) Memory : 16GB storage : 512GB local : 100GB local-lvm : 375GB
균형잡힌 K8s 리소스 계획
물리 vs 할당 리소스 (균형잡힌 오버커밋)
⚖️ BALANCED OVERCOMMIT 현황
| 구분 | 물리 | 할당 | 배수 | 안전성 |
|---|---|---|---|---|
| CPU | 4 Core | 20 vCPU | 5배 | ✅ 안전 |
| Memory | 15.41GB | 24GB | 1.56배 | ✅ 균형 |
| Disk | 512GB | 250GB | 0.49배 | ✅ 넉넉 |
주요 변경사항:
- 메모리 오버커밋: 1.7배 → 1.56배 (안전성 향상)
- 디스크 할당: 130GB → 250GB (실용성 향상)
- 워커 노드 완전 동일 스펙 (K8s 최적화)
VM 리소스 할당 (수정됨)
| VM | vCPU | Memory | Disk | 역할 |
|---|---|---|---|---|
| OpnSense | 2 | 2GB | 20GB | 방화벽/라우터 |
| K3s Master | 6 | 4GB | 30GB | 클러스터 컨트롤 플레인 |
| K3s Worker-1 | 6 | 9GB | 100GB | 워커 노드 |
| K3s Worker-2 | 6 | 9GB | 100GB | 워커 노드 |
균등 할당의 장점:
- ✅ K8s 동적 스케줄링에 최적화
- ✅ 노드 장애 시 완전한 페일오버 가능
- ✅ 관리 복잡성 제거
- ✅ 리소스 예측 가능성 향상
오버커밋이 안전한 이유 (간단 정리)
1. 📊 실제 사용률 차이
예시 - PostgreSQL:
- 할당: 2GB
- 평상시: 800MB (40% 사용)
- 피크시: 1.5GB (75% 사용)
예시 - Jenkins:
- 할당: 2.5GB
- 대기중: 300MB (12% 사용)
- 빌드중: 2.2GB (88% 사용)
2. ⏰ 시간대별 분산
실제 사용 패턴:
- 09:00-12:00: Jenkins 빌드 (높은 사용률)
- 14:00-17:00: 개발/테스트 (중간 사용률)
- 02:00-04:00: Elasticsearch 인덱싱 (높은 사용률)
- 23:00-07:00: 대부분 서비스 대기 (낮은 사용률)
→ 전체 서비스가 동시 피크 사용할 확률 매우 낮음
3. 🔄 메모리 공유 기술
KSM (Kernel Same-page Merging):
- Ubuntu 베이스 이미지: 4개 VM 공유
- Docker 베이스 레이어: 자동 중복 제거
- 시스템 라이브러리: 공통 부분 공유
→ 실제 메모리 사용량 30-40% 절약
서비스별 메모리 사용 패턴 (현실적)
🔴 무거운 서비스들 (2GB 이상)
| 서비스 | 할당 | 평상시 | 피크시 | 사용 시간대 |
|---|---|---|---|---|
| Jenkins | 2.5GB | 0.3GB | 2.2GB | 업무시간 빌드 |
| Elasticsearch | 2.5GB | 1.2GB | 2.3GB | 새벽 인덱싱 |
| Django API (2개) | 4GB | 2.5GB | 3.5GB | 사용자 트래픽 |
| Harbor | 2GB | 0.8GB | 1.8GB | 이미지 푸시시 |
| Prometheus | 2GB | 1.3GB | 1.8GB | 지속적 수집 |
🟡 중간 서비스들 (1-2GB)
| 서비스 | 할당 | 평상시 | 피크시 | 특징 |
|---|---|---|---|---|
| PostgreSQL | 2GB | 0.8GB | 1.5GB | 연결수에 따라 변동 |
| ArgoCD | 1.5GB | 0.9GB | 1.3GB | 배포시에만 증가 |
| MongoDB | 1.5GB | 0.7GB | 1.2GB | 로그 수집량에 따라 |
| Airflow | 1.5GB | 0.5GB | 1.3GB | 워크플로우 실행시 |
| Flutter Web (2개) | 3GB | 1.8GB | 2.5GB | 사용자 접속에 따라 |
🟢 가벼운 서비스들 (1GB 이하)
| 서비스 | 할당 | 평상시 | 피크시 | 특징 |
|---|---|---|---|---|
| Grafana | 1GB | 0.5GB | 0.8GB | 대시보드 조회시 증가 |
| Kibana | 1GB | 0.4GB | 0.7GB | 로그 검색시 증가 |
| Redis | 1GB | 0.3GB | 0.6GB | 캐시 데이터량에 따라 |
| Nginx | 0.5GB | 0.2GB | 0.4GB | 트래픽에 따라 선형 증가 |
워커 노드별 실제 사용 시나리오
시나리오 1: 정상 분산 (70% 확률)
Worker-1 (7.5GB 사용 / 9GB 할당):
Jenkins: 0.3GB (대기)
PostgreSQL: 0.8GB
Elasticsearch: 1.2GB
Django API replica-1: 1.2GB
Harbor: 0.8GB
Prometheus: 1.3GB
기타: 1.9GB
Worker-2 (7.2GB 사용 / 9GB 할당):
ArgoCD: 0.9GB
MongoDB: 0.7GB
Django API replica-2: 1.3GB
Flutter Web: 1.8GB
Grafana: 0.5GB
Airflow: 0.5GB
기타: 1.5GB시나리오 2: 빌드 + 인덱싱 동시 (20% 확률)
Worker-1 (8.7GB 사용 / 9GB 할당 - 안전):
Jenkins: 2.2GB (빌드 중)
Elasticsearch: 2.3GB (인덱싱)
PostgreSQL: 1.5GB
Django API: 1.2GB
기타: 1.5GB
Worker-2 (7.8GB 사용 / 9GB 할당):
Prometheus: 1.8GB (메트릭 증가)
ArgoCD: 1.3GB (배포 중)
Flutter Web: 2.5GB (트래픽 증가)
MongoDB: 1.2GB
기타: 1GB시나리오 3: 노드 장애 (5% 확률)
Worker-1 다운 시:
→ 모든 Pod가 Worker-2로 이동
→ Worker-2 필요 메모리: 약 15GB
→ 할당 메모리: 9GB
Priority Class 적용:
1. PostgreSQL, Redis (시스템 중요): 유지
2. Django API (비즈니스): 유지
3. Prometheus, Grafana (모니터링): 유지
4. Jenkins, Harbor (개발): Pending 상태
5. Jupyter, 기타 (옵션): Pending 상태
결과: 핵심 서비스는 유지, 개발 도구는 일시 중단디스크 사용량 예상
Worker-1 (100GB 할당)
OS + 시스템: 15GB
Docker 이미지들: 25GB
Jenkins 빌드 캐시: 20GB
Elasticsearch 인덱스: 20GB
PostgreSQL 데이터: 8GB
로그 파일들: 7GB
여유 공간: 5GB
Worker-2 (100GB 할당)
OS + 시스템: 15GB
Docker 이미지들: 20GB
Prometheus 메트릭: 25GB (15일 보관)
MongoDB 데이터: 15GB
애플리케이션 데이터: 10GB
백업 파일들: 10GB
여유 공간: 5GB
안전 운영 가이드
1. 🎯 리소스 모니터링 임계값
메모리 사용률 알림:
- 75% 이상: 주의 (6.7GB)
- 85% 이상: 경고 (7.6GB)
- 95% 이상: 긴급 (8.5GB)
디스크 사용률 알림:
- 80% 이상: 주의 (80GB)
- 90% 이상: 경고 (90GB)
- 95% 이상: 긴급 (95GB)2. 🔄 자동 대응 전략
HPA (Horizontal Pod Autoscaler):
- Django API: CPU 70% → replica 증가
- Flutter Web: 메모리 80% → replica 증가
Priority Classes:
- system-critical: DB, Redis
- business-critical: Django, Nginx
- development: Jenkins, Harbor
- monitoring: Prometheus, Grafana
- optional: Jupyter, 기타3. 📊 성능 최적화
Resource Limits 설정:
- requests: 최소 보장 리소스
- limits: 최대 사용 제한
- 메모리 leak 방지
- OOM 위험 최소화
Node Affinity:
- DB 서비스: SSD 우선 배치
- 계산 집약적: CPU 성능 우선
- I/O 집약적: 네트워크 성능 우선🎯 최종 평가
이 구성의 장점:
- ✅ 안전한 1.56배 메모리 오버커밋
- ✅ 충분한 디스크 공간 (250GB)
- ✅ 워커 노드 완전 동일 스펙
- ✅ 현실적인 서비스 배치 계획
- ✅ 장애 상황 대응 가능
예상 실제 사용률:
- CPU: 평상시 25%, 피크시 70%
- Memory: 평상시 18GB, 피크시 22GB
- Disk: 180-200GB (여유 50-70GB)
결론: N100 미니PC로 엔터프라이즈급 개발환경 구축 가능! 🚀
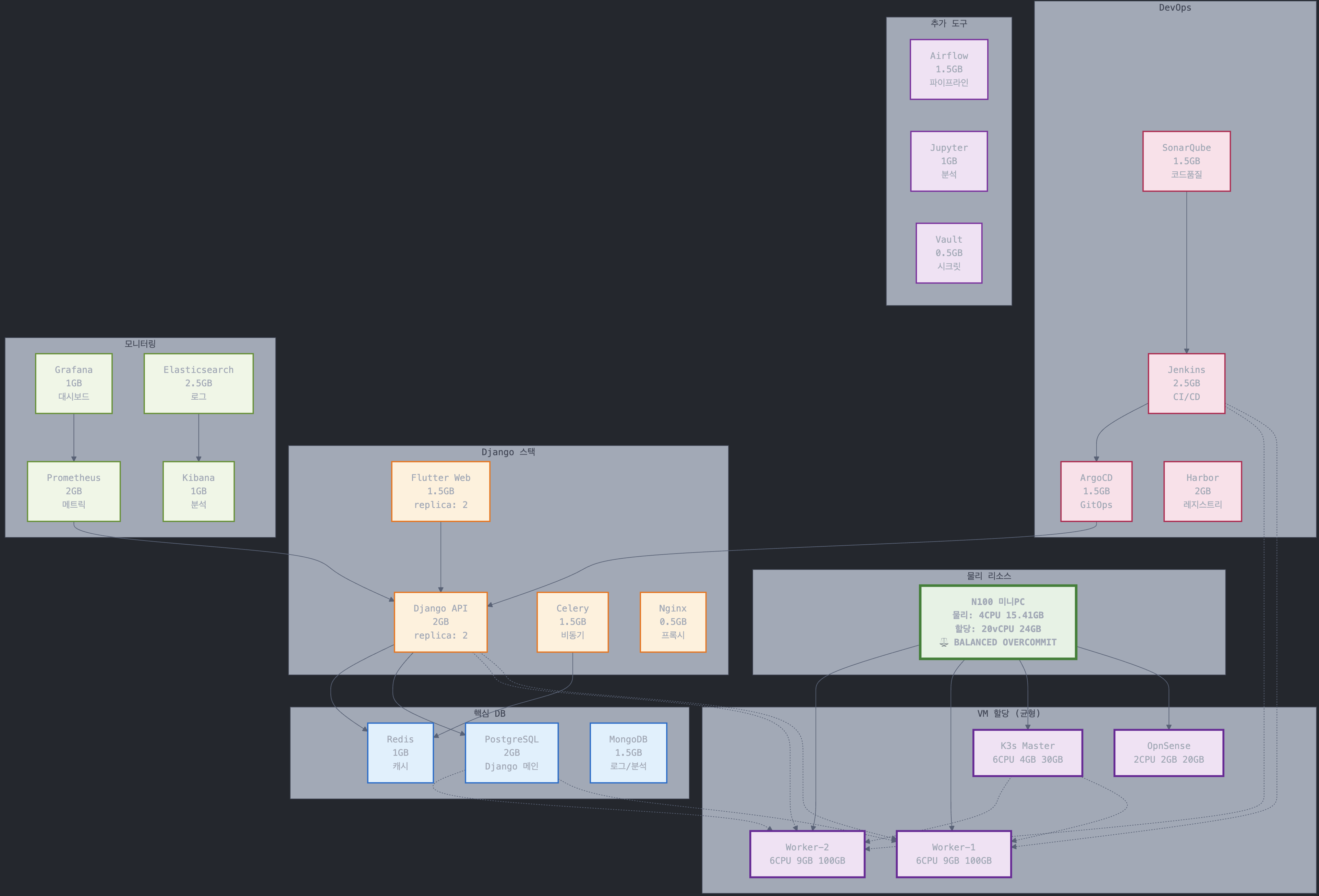
다이어그램
Info
K8s 클러스터에서는 실제로 서비스들이 특정 노드에 고정되지 않고, 클러스터 전체에 분산 배치 됩니다. 아래 다이어 그램은 “예상 배치 및 리소스 계획” 입니다.
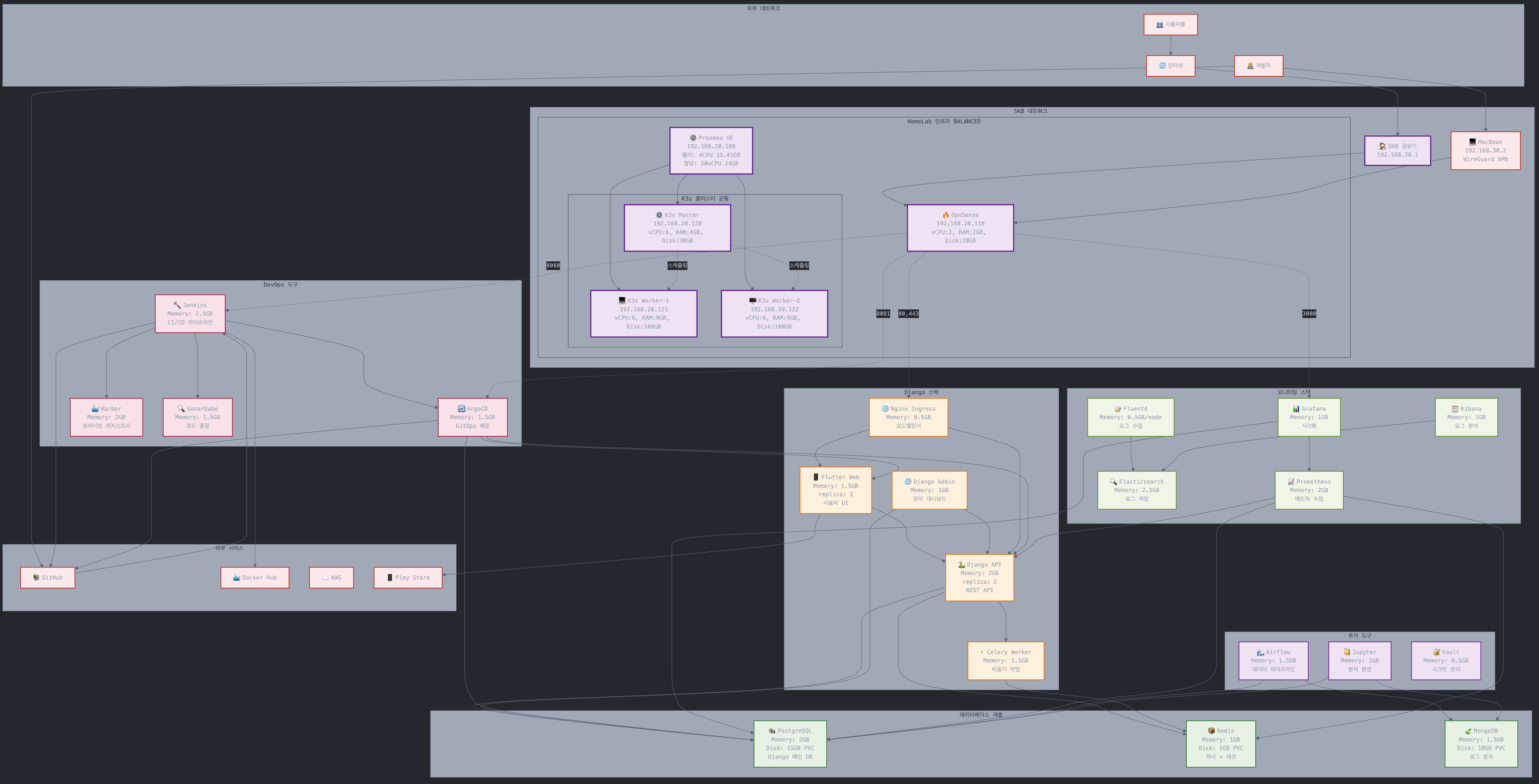
더 간단하게 표현한 다이어그램.